Voice cloning (Part one)

The field of text-to-speech (TTS) synthesis has witnessed remarkable progress in recent years, fueled by advancements in deep learning and the availability of large-scale datasets. Modern TTS systems are capable of producing highly realistic and expressive speech, blurring the lines between synthetic and natural voices. This project guide delves into two prominent models at the forefront of this revolution: StyleTTS 2 and Tortoise-TTS. Both models represent innovative approaches to voice cloning and speech synthesis, each leveraging distinct techniques to achieve impressive results.
This guide serves as a starting point for exploring these powerful TTS systems, providing a concise overview of their core principles, methodologies, and key features. Furthermore, this guide will provide code examples to illustrate how to use each project. Please note that these examples are for educational and research purposes only. I am not responsible for any illegal or unethical usage of these technologies. While this guide highlights these two specific projects, it is crucial to acknowledge that the open-source community offers a vibrant ecosystem of TTS models, each with its own strengths and limitations. Readers are encouraged to explore other projects and compare their performance and functionalities to gain a broader understanding of the evolving landscape of voice cloning technology.
This project guide is structured into the following sections:
-
StyleTTS 2: This section explores the architecture and capabilities of StyleTTS 2, focusing on its novel use of style diffusion and adversarial training with large speech language models (SLMs). We will delve into its key components, including style diffusion, SLM adversarial training, differentiable duration modeling, and end-to-end training.
-
Tortoise-TTS: This section investigates the unique approach of Tortoise-TTS, highlighting its combination of autoregressive decoders and diffusion models (DDPMs) inspired by advancements in image generation. We will examine its core features, including the use of CLVP for re-ranking, conditioning input, the "Tortoise Trick," and the importance of large-scale training.
StyleTTS 2: Leveraging Style Diffusion and SLM Adversarial Training
StyleTTS 2 distinguishes itself through its innovative application of style diffusion and adversarial training with large speech language models (SLMs). This model effectively captures and synthesizes diverse speech styles without relying on reference audio, resulting in highly expressive and natural-sounding speech.
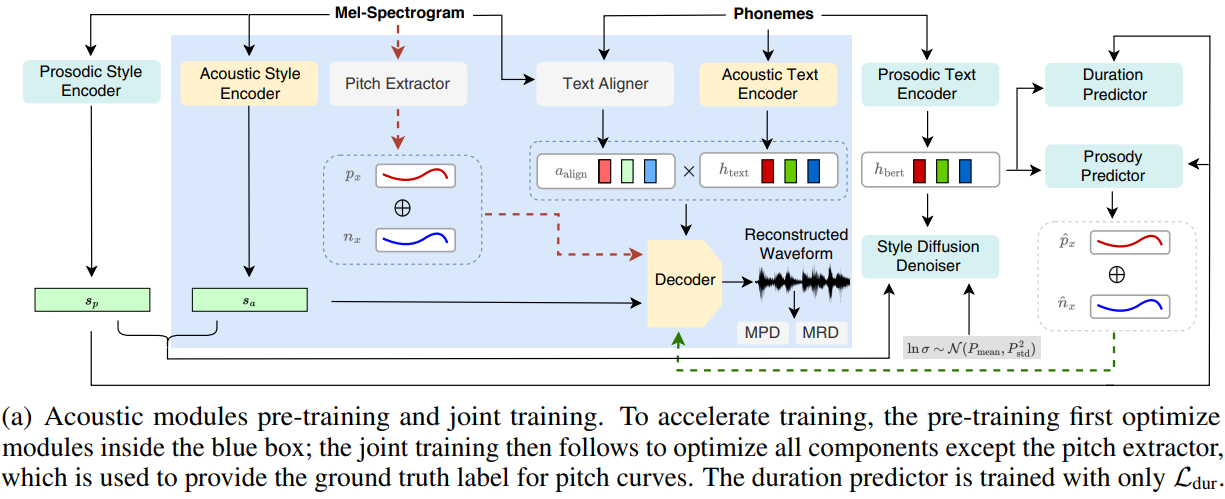
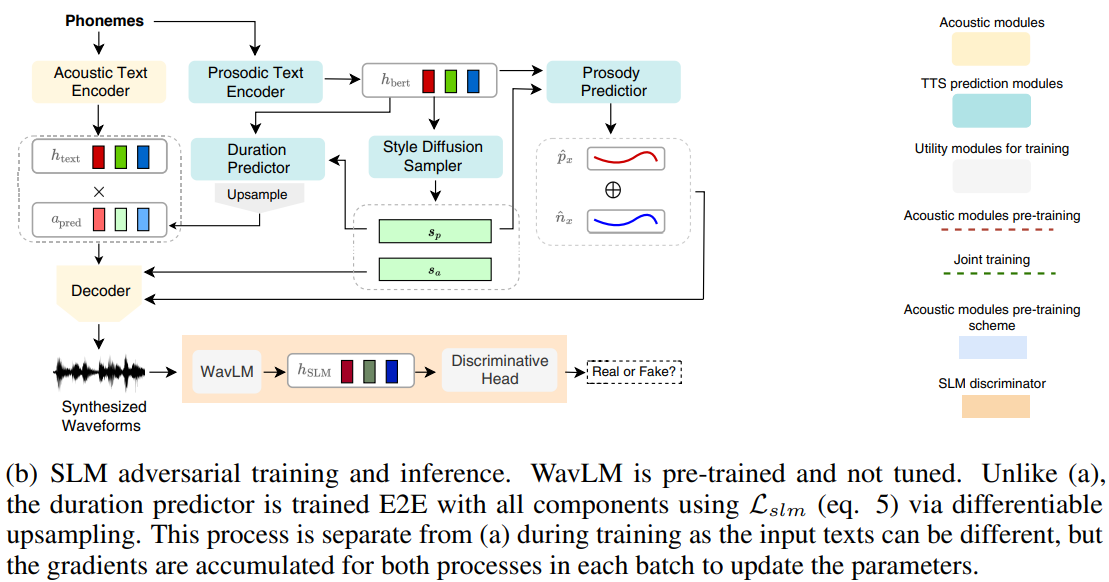
Figure 1: Training and inference scheme of StyleTTS 2 for the single-speaker case. For the multispeaker case, the acoustic and prosodic style encoders (denoted as E) first take reference audio xref of the target speaker and produce a reference style vector c = E(xref). The style diffusion model then takes c as a reference to sample sp and sa that correspond to the speaker in xref.
Key components of StyleTTS 2 include:
-
Style Diffusion: This novel technique models speech styles as a latent random variable, allowing for efficient sampling and manipulation of different styles conditioned on the input text. By leveraging a diffusion model, StyleTTS 2 generates diverse and expressive speech without needing reference audio.
-
SLM Adversarial Training: Pre-trained SLMs like WavLM serve as discriminators, providing feedback to the model and enhancing the naturalness of synthesized speech. This leverages the rich acoustic and semantic knowledge embedded within SLMs to improve speech quality significantly.
-
Differentiable Duration Modeling: This innovative approach enables end-to-end training with SLM discriminators, addressing instability issues prevalent in previous methods. This allows the model to learn directly from SLM feedback, leading to more accurate and natural duration control.
-
End-to-End Training: The entire StyleTTS 2 architecture is trained jointly, optimizing all components, including waveform generation. This holistic approach further enhances the overall quality and coherence of synthesized speech.
StyleTTS 2 Voice Cloning Code Example
Setting up the Environment and Dependencies
This initial block gets everything ready. It clones the StyleTTS2 repository, installs necessary Python packages, downloads a pre-trained model, and prepares reference audio.
%%shell
git clone https://github.com/yl4579/StyleTTS2.git
cd StyleTTS2
pip install SoundFile torchaudio munch torch pydub pyyaml librosa nltk matplotlib accelerate transformers phonemizer einops einops-exts tqdm typing-extensions git+https://github.com/resemble-ai/monotonic_align.git
sudo apt-get install espeak-ng
git-lfs clone https://huggingface.co/yl4579/StyleTTS2-LibriTTS
mv StyleTTS2-LibriTTS/Models .
mv StyleTTS2-LibriTTS/reference_audio.zip .
unzip reference_audio.zip
mv reference_audio Demo/reference_audio
pip install yt_dlp
Importing Libraries, Setting Seeds, and Defining Helper Functions
This section imports essential libraries, sets random seeds for reproducibility, and defines some utility functions. These functions handle tasks like preprocessing audio, computing style embeddings, and converting text to phonemes.
import nltk
nltk.download('punkt')
%cd StyleTTS2
import torch
torch.manual_seed(0)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
import random
random.seed(0)
import numpy as np
np.random.seed(0)
# load packages
import time
import random
import yaml
from munch import Munch
import numpy as np
import torch
from torch import nn
import torch.nn.functional as F
import torchaudio
import librosa
from nltk.tokenize import word_tokenize
from models import *
from utils import *
from text_utils import TextCleaner
textclenaer = TextCleaner()
Loading Pre-trained Models and Configuration
Here, we load the various pre-trained models that StyleTTS 2 relies on, including an ASR model, a pitch extractor, and a BERT model. We also load the configuration file, which contains important parameters for the model.
%matplotlib inline
to_mel = torchaudio.transforms.MelSpectrogram(
n_mels=80, n_fft=2048, win_length=1200, hop_length=300)
mean, std = -4, 4
def length_to_mask(lengths):
mask = torch.arange(lengths.max()).unsqueeze(0).expand(lengths.shape[0], -1).type_as(lengths)
mask = torch.gt(mask+1, lengths.unsqueeze(1))
return mask
def preprocess(wave):
wave_tensor = torch.from_numpy(wave).float()
mel_tensor = to_mel(wave_tensor)
mel_tensor = (torch.log(1e-5 + mel_tensor.unsqueeze(0)) - mean) / std
return mel_tensor
def compute_style(path):
wave, sr = librosa.load(path, sr=24000)
audio, index = librosa.effects.trim(wave, top_db=30)
if sr != 24000:
audio = librosa.resample(audio, sr, 24000)
mel_tensor = preprocess(audio).to(device)
with torch.no_grad():
ref_s = model.style_encoder(mel_tensor.unsqueeze(1))
ref_p = model.predictor_encoder(mel_tensor.unsqueeze(1))
return torch.cat([ref_s, ref_p], dim=1)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# load phonemizer
import phonemizer
global_phonemizer = phonemizer.backend.EspeakBackend(language='en-us', preserve_punctuation=True, with_stress=True)
config = yaml.safe_load(open("Models/LibriTTS/config.yml"))
# load pretrained ASR model
ASR_config = config.get('ASR_config', False)
ASR_path = config.get('ASR_path', False)
text_aligner = load_ASR_models(ASR_path, ASR_config)
# load pretrained F0 model
F0_path = config.get('F0_path', False)
pitch_extractor = load_F0_models(F0_path)
# load BERT model
from Utils.PLBERT.util import load_plbert
BERT_path = config.get('PLBERT_dir', False)
plbert = load_plbert(BERT_path)
model_params = recursive_munch(config['model_params'])
model = build_model(model_params, text_aligner, pitch_extractor, plbert)
_ = [model[key].eval() for key in model]
_ = [model[key].to(device) for key in model]
params_whole = torch.load("Models/LibriTTS/epochs_2nd_00020.pth", map_location='cpu')
params = params_whole['net']
for key in model:
if key in params:
print('%s loaded' % key)
try:
model[key].load_state_dict(params[key])
except:
from collections import OrderedDict
state_dict = params[key]
new_state_dict = OrderedDict()
for k, v in state_dict.items():
name = k[7:] # remove `module.`
new_state_dict[name] = v
# load params
model[key].load_state_dict(new_state_dict, strict=False)
# except:
# _load(params[key], model[key])
_ = [model[key].eval() for key in model]
Setting up the Diffusion Sampler and Inference Functions
This block sets up the diffusion sampler, which is a key component of StyleTTS 2. It also defines the main inference functions (
inference,LFinference,STinference) that we'll use to generate speech. This is like configuring the core engine that will drive the speech synthesis process.
from Modules.diffusion.sampler import DiffusionSampler, ADPM2Sampler, KarrasSchedule
sampler = DiffusionSampler(
model.diffusion.diffusion,
sampler=ADPM2Sampler(),
sigma_schedule=KarrasSchedule(sigma_min=0.0001, sigma_max=3.0, rho=9.0), # empirical parameters
clamp=False
)
def inference(text, ref_s, alpha = 0.3, beta = 0.7, diffusion_steps=5, embedding_scale=1):
text = text.strip()
ps = global_phonemizer.phonemize([text])
ps = word_tokenize(ps[0])
ps = ' '.join(ps)
tokens = textclenaer(ps)
tokens.insert(0, 0)
tokens = torch.LongTensor(tokens).to(device).unsqueeze(0)
with torch.no_grad():
input_lengths = torch.LongTensor([tokens.shape[-1]]).to(device)
text_mask = length_to_mask(input_lengths).to(device)
t_en = model.text_encoder(tokens, input_lengths, text_mask)
bert_dur = model.bert(tokens, attention_mask=(~text_mask).int())
d_en = model.bert_encoder(bert_dur).transpose(-1, -2)
s_pred = sampler(noise = torch.randn((1, 256)).unsqueeze(1).to(device),
embedding=bert_dur,
embedding_scale=embedding_scale,
features=ref_s, # reference from the same speaker as the embedding
num_steps=diffusion_steps).squeeze(1)
s = s_pred[:, 128:]
ref = s_pred[:, :128]
ref = alpha * ref + (1 - alpha) * ref_s[:, :128]
s = beta * s + (1 - beta) * ref_s[:, 128:]
d = model.predictor.text_encoder(d_en,
s, input_lengths, text_mask)
x, _ = model.predictor.lstm(d)
duration = model.predictor.duration_proj(x)
duration = torch.sigmoid(duration).sum(axis=-1)
pred_dur = torch.round(duration.squeeze()).clamp(min=1)
pred_aln_trg = torch.zeros(input_lengths, int(pred_dur.sum().data))
c_frame = 0
for i in range(pred_aln_trg.size(0)):
pred_aln_trg[i, c_frame:c_frame + int(pred_dur[i].data)] = 1
c_frame += int(pred_dur[i].data)
# encode prosody
en = (d.transpose(-1, -2) @ pred_aln_trg.unsqueeze(0).to(device))
if model_params.decoder.type == "hifigan":
asr_new = torch.zeros_like(en)
asr_new[:, :, 0] = en[:, :, 0]
asr_new[:, :, 1:] = en[:, :, 0:-1]
en = asr_new
F0_pred, N_pred = model.predictor.F0Ntrain(en, s)
asr = (t_en @ pred_aln_trg.unsqueeze(0).to(device))
if model_params.decoder.type == "hifigan":
asr_new = torch.zeros_like(asr)
asr_new[:, :, 0] = asr[:, :, 0]
asr_new[:, :, 1:] = asr[:, :, 0:-1]
asr = asr_new
out = model.decoder(asr,
F0_pred, N_pred, ref.squeeze().unsqueeze(0))
return out.squeeze().cpu().numpy()[..., :-50] # weird pulse at the end of the model, need to be fixed later
def LFinference(text, s_prev, ref_s, alpha = 0.3, beta = 0.7, t = 0.7, diffusion_steps=5, embedding_scale=1):
text = text.strip()
ps = global_phonemizer.phonemize([text])
ps = word_tokenize(ps[0])
ps = ' '.join(ps)
ps = ps.replace('``', '"')
ps = ps.replace("''", '"')
tokens = textclenaer(ps)
tokens.insert(0, 0)
tokens = torch.LongTensor(tokens).to(device).unsqueeze(0)
with torch.no_grad():
input_lengths = torch.LongTensor([tokens.shape[-1]]).to(device)
text_mask = length_to_mask(input_lengths).to(device)
t_en = model.text_encoder(tokens, input_lengths, text_mask)
bert_dur = model.bert(tokens, attention_mask=(~text_mask).int())
d_en = model.bert_encoder(bert_dur).transpose(-1, -2)
s_pred = sampler(noise = torch.randn((1, 256)).unsqueeze(1).to(device),
embedding=bert_dur,
embedding_scale=embedding_scale,
features=ref_s, # reference from the same speaker as the embedding
num_steps=diffusion_steps).squeeze(1)
if s_prev is not None:
# convex combination of previous and current style
s_pred = t * s_prev + (1 - t) * s_pred
s = s_pred[:, 128:]
ref = s_pred[:, :128]
ref = alpha * ref + (1 - alpha) * ref_s[:, :128]
s = beta * s + (1 - beta) * ref_s[:, 128:]
s_pred = torch.cat([ref, s], dim=-1)
d = model.predictor.text_encoder(d_en,
s, input_lengths, text_mask)
x, _ = model.predictor.lstm(d)
duration = model.predictor.duration_proj(x)
duration = torch.sigmoid(duration).sum(axis=-1)
pred_dur = torch.round(duration.squeeze()).clamp(min=1)
pred_aln_trg = torch.zeros(input_lengths, int(pred_dur.sum().data))
c_frame = 0
for i in range(pred_aln_trg.size(0)):
pred_aln_trg[i, c_frame:c_frame + int(pred_dur[i].data)] = 1
c_frame += int(pred_dur[i].data)
# encode prosody
en = (d.transpose(-1, -2) @ pred_aln_trg.unsqueeze(0).to(device))
if model_params.decoder.type == "hifigan":
asr_new = torch.zeros_like(en)
asr_new[:, :, 0] = en[:, :, 0]
asr_new[:, :, 1:] = en[:, :, 0:-1]
en = asr_new
F0_pred, N_pred = model.predictor.F0Ntrain(en, s)
asr = (t_en @ pred_aln_trg.unsqueeze(0).to(device))
if model_params.decoder.type == "hifigan":
asr_new = torch.zeros_like(asr)
asr_new[:, :, 0] = asr[:, :, 0]
asr_new[:, :, 1:] = asr[:, :, 0:-1]
asr = asr_new
out = model.decoder(asr,
F0_pred, N_pred, ref.squeeze().unsqueeze(0))
return out.squeeze().cpu().numpy()[..., :-100], s_pred # weird pulse at the end of the model, need to be fixed later
def STinference(text, ref_s, ref_text, alpha = 0.3, beta = 0.7, diffusion_steps=5, embedding_scale=1):
text = text.strip()
ps = global_phonemizer.phonemize([text])
ps = word_tokenize(ps[0])
ps = ' '.join(ps)
tokens = textclenaer(ps)
tokens.insert(0, 0)
tokens = torch.LongTensor(tokens).to(device).unsqueeze(0)
ref_text = ref_text.strip()
ps = global_phonemizer.phonemize([ref_text])
ps = word_tokenize(ps[0])
ps = ' '.join(ps)
ref_tokens = textclenaer(ps)
ref_tokens.insert(0, 0)
ref_tokens = torch.LongTensor(ref_tokens).to(device).unsqueeze(0)
with torch.no_grad():
input_lengths = torch.LongTensor([tokens.shape[-1]]).to(device)
text_mask = length_to_mask(input_lengths).to(device)
t_en = model.text_encoder(tokens, input_lengths, text_mask)
bert_dur = model.bert(tokens, attention_mask=(~text_mask).int())
d_en = model.bert_encoder(bert_dur).transpose(-1, -2)
ref_input_lengths = torch.LongTensor([ref_tokens.shape[-1]]).to(device)
ref_text_mask = length_to_mask(ref_input_lengths).to(device)
ref_bert_dur = model.bert(ref_tokens, attention_mask=(~ref_text_mask).int())
s_pred = sampler(noise = torch.randn((1, 256)).unsqueeze(1).to(device),
embedding=bert_dur,
embedding_scale=embedding_scale,
features=ref_s, # reference from the same speaker as the embedding
num_steps=diffusion_steps).squeeze(1)
s = s_pred[:, 128:]
ref = s_pred[:, :128]
ref = alpha * ref + (1 - alpha) * ref_s[:, :128]
s = beta * s + (1 - beta) * ref_s[:, 128:]
d = model.predictor.text_encoder(d_en,
s, input_lengths, text_mask)
x, _ = model.predictor.lstm(d)
duration = model.predictor.duration_proj(x)
duration = torch.sigmoid(duration).sum(axis=-1)
pred_dur = torch.round(duration.squeeze()).clamp(min=1)
pred_aln_trg = torch.zeros(input_lengths, int(pred_dur.sum().data))
c_frame = 0
for i in range(pred_aln_trg.size(0)):
pred_aln_trg[i, c_frame:c_frame + int(pred_dur[i].data)] = 1
c_frame += int(pred_dur[i].data)
# encode prosody
en = (d.transpose(-1, -2) @ pred_aln_trg.unsqueeze(0).to(device))
if model_params.decoder.type == "hifigan":
asr_new = torch.zeros_like(en)
asr_new[:, :, 0] = en[:, :, 0]
asr_new[:, :, 1:] = en[:, :, 0:-1]
en = asr_new
F0_pred, N_pred = model.predictor.F0Ntrain(en, s)
asr = (t_en @ pred_aln_trg.unsqueeze(0).to(device))
if model_params.decoder.type == "hifigan":
asr_new = torch.zeros_like(asr)
asr_new[:, :, 0] = asr[:, :, 0]
asr_new[:, :, 1:] = asr[:, :, 0:-1]
asr = asr_new
out = model.decoder(asr,
F0_pred, N_pred, ref.squeeze().unsqueeze(0))
return out.squeeze().cpu().numpy()[..., :-50] # weird pulse at the end of the model, need to be fixed later
Downloading Reference Audio from YouTube
Here we create a function to download audio from YouTube, which we can use as reference audio for voice cloning.
from yt_dlp import YoutubeDL
def download_audio(youtube_link, output_path="/content"):
"""Downloads audio from a YouTube video.
Args:
youtube_link: The URL of the YouTube video.
output_path: The path to save the audio file. Defaults to "audio".
"""
ydl_opts = {
'format': 'bestaudio/best',
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'wav',
'preferredquality': '192',
}],
'outtmpl': f'{output_path}/%(NA)s.%(ext)s'
}
with YoutubeDL(ydl_opts) as ydl:
ydl.download([youtube_link])
print(f"Audio downloaded from {youtube_link} and saved to {output_path}")
download_audio("https://www.youtube.com/watch?v=VID") # replace The VID with yours
Simple Inference with StyleTTS 2
Now we get to use the model .. We specify a reference audio file and some text, then use the
inferencefunction to generate speech. We also calculate the Real-Time Factor (RTF) to see how fast the synthesis is.
reference_dicts = {}
reference_dicts['Voice_NAME'] = "/content/NA.wav" # change the voice reference name (ex: Trump) , also the file path of your reference file (should be in wav format)
text = """
StyleTTS 2 is a text to speech model that leverages style diffusion and adversarial training with large speech language models to achieve human level text to speech synthesis
"""
# Simple Usage
noise = torch.randn(1,1,256).to(device)
for k, path in reference_dicts.items():
ref_s = compute_style(path)
start = time.time()
wav = inference(text, ref_s, alpha=0.3, beta=0.7, diffusion_steps=5, embedding_scale=1)
rtf = (time.time() - start) / (len(wav) / 24000)
print(f"RTF = {rtf:5f}")
import IPython.display as ipd
print(k + ' Synthesized:')
display(ipd.Audio(wav, rate=24000, normalize=False))
print('Reference:')
display(ipd.Audio(path, rate=24000, normalize=False))
Exploring Different Emotional Styles
This section demonstrates how to control the emotional style of the generated speech by providing different text prompts with varying emotions.
Alpha and Beta is the factor to determine much we use the style sampled based on the text instead of the reference. The higher the value of alpha and beta, the more suitable the style it is to the text but less similar to the reference. Using higher beta makes the synthesized speech more emotional, at the cost of lower similarity to the reference. alpha determines the timbre of the speaker while beta determines the prosody.
texts = {}
ref_s = compute_style("/content/NA.wav")
texts['Happy'] = "We are happy to invite you to join us on a journey to the past, where we will visit the most amazing monuments ever built by human hands."
texts['Sad'] = "I am sorry to say that we have suffered a severe setback in our efforts to restore prosperity and confidence."
texts['Angry'] = "The field of astronomy is a joke! Its theories are based on flawed observations and biased interpretations!"
texts['Surprised'] = "I can't believe it! You mean to tell me that you have discovered a new species of bacteria in this pond?"
for k,v in texts.items():
wav = inference(v, ref_s, diffusion_steps=10, alpha=0.3, beta=0.7, embedding_scale=1)
print(k + ": ")
display(ipd.Audio(wav, rate=24000, normalize=False))
Long-Form Narration with StyleTTS 2
Finally this code here shows how to generate speech for longer passages of text using the
LFinferencefunction. This is particularly useful for tasks like audiobook narration or creating longer voice-overs.
# Longform Narration
passage = """
If the supply of fruit is greater than the family needs,it may be made a source of income by sending the fresh fruit to the market if there is one near enough, or by preserving, canning, and making jelly for sale. To make such an enterprise a success the fruit and work must be first class. There is magic in the word "Homemade," when the product appeals to the eye and the palate; but many careless and incompetent people have found to their sorrow that this word has not magic enough to float inferior goods on the market. As a rule large canning and preserving establishments are clean and have the best appliances, and they employ chemists and skilled labor. The home product must be very good to compete with the attractive goods that are sent out from such establishments. Yet for first class home made products there is a market in all large cities. All first-class grocers have customers who purchase such goods.
"""
path = "/content/NA.wav"
s_ref = compute_style(path)
sentences = passage.split('.') # simple split by comma
wavs = []
s_prev = None
for text in sentences:
if text.strip() == "": continue
text += '.' # add it back
wav, s_prev = LFinference(text,
s_prev,
s_ref,
alpha = 0.3,
beta = 0.9, # make it more suitable for the text
t = 0.7,
diffusion_steps=10, embedding_scale=1.5)
wavs.append(wav)
print('Synthesized: ')
display(ipd.Audio(np.concatenate(wavs), rate=24000, normalize=False))
print('Reference: ')
display(ipd.Audio(path, rate=24000, normalize=False))
StyleTTS 2 has demonstrated state-of-the-art performance on various benchmarks, achieving impressive results in both subjective and objective evaluations. Its ability to generate diverse and expressive speech without reference audio opens up exciting possibilities for voice cloning and personalized speech synthesis applications.
Tortoise-TTS: Combining Autoregressive Decoders and Diffusion Models
Tortoise-TTS takes a different approach, drawing inspiration from advancements in image generation by combining autoregressive decoders and diffusion models (DDPMs). This unique architecture allows Tortoise-TTS to achieve high-quality speech synthesis by leveraging the strengths of both approaches.
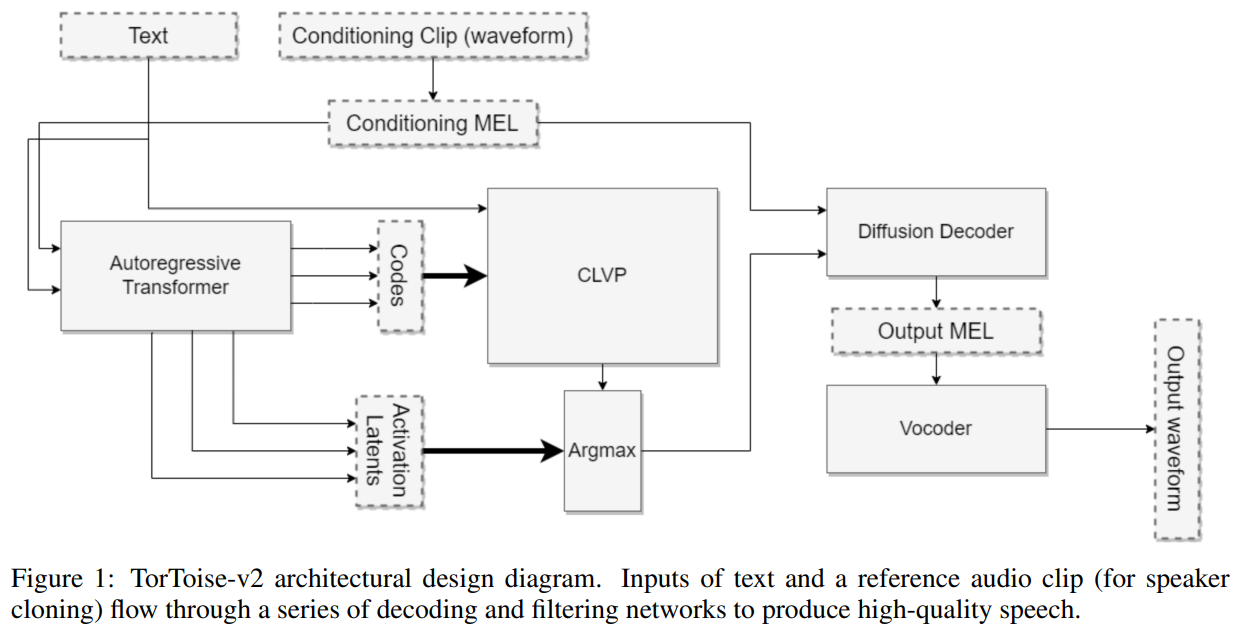
Key features of Tortoise-TTS include:
-
Autoregressive Decoders and DDPMs: An autoregressive transformer converts text into a sequence of "speech tokens," which are then decoded into a high-quality MEL spectrogram by a DDPM. This combination allows for efficient and accurate text-to-speech conversion.
-
Contrastive Language-Voice Pretrained (CLVP) Model: Inspired by DALL-E, Tortoise-TTS employs a CLIP-like model trained on text and speech pairs to score the outputs of the autoregressive decoder. This enables the selection of the highest quality candidate before the computationally expensive DDPM decoding.
-
Conditioning Input: To improve vocal characteristics and reduce the search space, Tortoise-TTS incorporates reference audio clips from the target speaker as an additional input, conditioning both the autoregressive and diffusion models.
-
Tortoise Trick: Fine-tuning the DDPM on the autoregressive latent space rather than discrete tokens significantly improves efficiency and quality.
-
Large-Scale Training: Tortoise-TTS benefits from training on a massive dataset combining LibriTTS, HiFiTTS, and an independently collected dataset of 49,000 hours of audiobooks and podcasts.
Tortoise-TTS Voice Cloning Code Example
Setting up the Environment
Here We're installing necessary packages, cloning the Tortoise-TTS repository, and installing its specific dependencies.
%%capture
!pip3 install -U scipy
!git clone https://github.com/jnordberg/tortoise-tts.git
%cd tortoise-tts
!pip3 install -r requirements.txt
!pip3 install transformers==4.19.0 einops==0.5.0 rotary_embedding_torch==0.1.5 unidecode==1.3.5
!python3 setup.py install
!pip install yt_dlp
Importing Libraries and Initializing Tortoise-TTS
Now we're importing the code libraries we'll need to work with audio and Tortoise-TTS. We also create a
TextToSpeechobject, which is our main interface for interacting with the model. This downloads the necessary model files from the internet, so it might take a little while.
import torch
import torchaudio
import torch.nn as nn
import torch.nn.functional as F
import IPython
from tortoise.api import TextToSpeech
from tortoise.utils.audio import load_audio, load_voice, load_voices
# This will download all the models used by Tortoise from the HuggingFace hub.
tts = TextToSpeech()
Defining Text and Voice Parameters
import os
text = """
This methodology of improving performance need not be confined to images. This
paper describes a way to apply advances in the image generative domain to speech
synthesis. The result is TorToise - an expressive, multi-voice text-to-speech system
"""
# Name of the voice
CUSTOM_VOICE_NAME = "ANY" # for example Trump or any other name ..
# preset is the speed of the clone voice
preset = "standard"
custom_voice_folder = f"tortoise/voices/{CUSTOM_VOICE_NAME}"
os.makedirs(custom_voice_folder)
Here, we specify the text we want to convert to speech and set up some parameters for our custom voice. We're creating a folder to store the voice data and choosing a name for it. We also define the
preset, which controls the speed of the generated speech.
Obtaining Voice Data (YouTube or Upload)
This section gives us two options for getting audio data to train our custom voice: either downloading it from a YouTube video using
yt-dlpor uploading WAV files directly.
Option 1: Download from YouTube :
from yt_dlp import YoutubeDL
def download_audio(youtube_link):
"""Downloads audio from a YouTube video.
Args:
youtube_link: The URL of the YouTube video.
output_path: The path to save the audio file. Defaults to "audio".
"""
ydl_opts = {
'format': 'bestaudio/best',
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'wav',
'preferredquality': '192',
}],
'outtmpl': f'{custom_voice_folder}/%(0)s.%(ext)s'
}
with YoutubeDL(ydl_opts) as ydl:
ydl.download([youtube_link])
print(f"Audio downloaded from {youtube_link} and saved to {custom_voice_folder}")
download_audio("https://www.youtube.com/watch?v=VID") # replace The VID with yours
Option 2: Upload from Computer :
from google.colab import files
for i, file_data in enumerate(files.upload().values()):
with open(os.path.join(custom_voice_folder, f'{i}.wav'), 'wb') as f:
f.write(file_data)
Generating Speech with the Custom Voice
# Generating speech with the custom voice.
voice_samples, conditioning_latents = load_voice(CUSTOM_VOICE_NAME)
gen = tts.tts_with_preset(text, voice_samples=voice_samples, conditioning_latents=conditioning_latents,
preset=preset)
torchaudio.save(f'generated-{CUSTOM_VOICE_NAME}.wav', gen.squeeze(0).cpu(), 24000)
IPython.display.Audio(f'generated-{CUSTOM_VOICE_NAME}.wav')
Finally, the magic happens.. We load the voice data we collected, use the
tts_with_presetfunction to generate speech based on our input text and chosen voice, and then save the result as a WAV file. We can even listen to it directly in the notebook.
Through this combination of innovative techniques and large-scale training, Tortoise-TTS achieves impressive results in terms of speech quality and naturalness. Its ability to leverage advancements from other domains, such as image generation, highlights the potential for cross-domain learning in pushing the boundaries of speech synthesis technology.
So, we've journeyed through the intricate workings of both Tortoise-TTS and StyleTTS 2, two impressive examples of how far text-to-speech technology has come. They offer powerful tools for generating realistic and expressive synthetic voices, opening up a world of possibilities for various applications.
It's important to remember that these are just two examples among many in the ever-evolving landscape of voice cloning. The open-source community is constantly pushing the boundaries, and there might be even better models out there depending on your specific needs.
The real magic often lies in customization. You can take these pre-trained models and fine-tune them with your own data to create voices that are even more unique and tailored to your use case. This is especially helpful for capturing specific slang, accents, or other nuances that might not be present in the original training data.
The best voice cloning model for you depends on your individual requirements and the effort you're willing to invest in training and customization. The journey of exploring these technologies is ongoing, and with continuous learning and experimentation, you can unlock the full potential of voice cloning for your projects.
Happy synthesizing!!