A Step-by-Step Guide to Integrating Self-RAG, Corrective RAG, and Adaptive RAG
In this project, we will create a new Retrieval-Augmented Generation (RAG) pipeline by combining innovative techniques from three advanced frameworks: Self-RAG, Corrective RAG, and Adaptive RAG. Our goal is to build a system that intelligently handles questions of varying complexity, ensures the accuracy of information, and provides useful answers. By integrating the best features of these methods, we aim to develop a powerful tool for improving question-answering tasks.
Self-RAG
Self-RAG (Self-Reflective Retrieval-Augmented Generation) is a framework designed to improve the quality and factual accuracy of large language models (LLMs). Unlike traditional RAG methods that simply retrieve and use documents, Self-RAG enhances LLMs by adding a self-reflection mechanism. This approach allows the model to generate responses and then review and refine those responses based on the retrieved information. Self-RAG uses reflection tokens to guide the model in checking its own outputs for accuracy and relevance, which helps in producing more accurate and reliable answers for various tasks.
Corrective RAG
Corrective RAG (CRAG) builds on the Retrieval-Augmented Generation (RAG) framework by adding a self-correcting mechanism to address the limitations of RAG models. While RAG enhances LLMs by incorporating external knowledge, CRAG goes a step further by evaluating the quality of retrieved documents and making corrections as needed. CRAG uses a retrieval evaluator to determine if the documents are relevant and, if not, performs a web search to find better information. This two-step process — assessing the retrieved content and then correcting it — ensures that the final output is more accurate and trustworthy.
Adaptive RAG
Adaptive RAG is an advanced strategy for Retrieval-Augmented Generation that dynamically adjusts the retrieval approach based on the complexity of the user’s query. Unlike static RAG methods, Adaptive RAG uses a classifier to assess the complexity of a question and selects the most suitable retrieval strategy accordingly. This adaptive approach helps in managing both simple and complex queries more effectively by routing questions to different RAG methods or even skipping retrieval for straightforward cases. The goal of Adaptive RAG is to improve the efficiency and accuracy of question-answering systems by tailoring the retrieval process to the specific needs of each query.
🦜🕸️LangGraph
LangGraph is a library for building stateful, multi-actor applications with LLMs, used to create agent and multi-agent workflows. Compared to other LLM frameworks, it offers these core benefits: cycles, controllability, and persistence. LangGraph allows you to define flows that involve cycles, essential for most agentic architectures, differentiating it from DAG-based solutions. As a very low-level framework, it provides fine-grained control over both the flow and state of your application, crucial for creating reliable agents. Additionally, LangGraph includes built-in persistence, enabling advanced human-in-the-loop and memory features.
Code Time
Setup The Environment
First, set the environment variable for the Cohere API key to authenticate and access the Cohere models for this project.
import os
os.environ["CO_API_KEY"] = ""
We need to install several essential Python packages.
! pip install langchain_core langchain langchain_cohere langchain-community langchain-chroma duckduckgo-search
We import necessary modules for the project, including Chroma for managing document vectors, RecursiveCharacterTextSplitter for breaking text into manageable chunks, PyPDFDirectoryLoader for loading PDF documents, CohereEmbeddings for creating embeddings, and Cohere for using the Cohere language model.
# import
from langchain_chroma import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFDirectoryLoader
from langchain_cohere import CohereEmbeddings
from langchain_community.llms import Cohere
Next, we initialize the Cohere language model with the command-r-plus variant, setting the maximum token limit for responses to 1024 and configuring the temperature for output variability to 0.2.
llm = Cohere(model="command-r-plus", max_tokens=1024, temperature=0.2)
Create The Retriever
We define the Retriever function to load PDF documents from a specified folder, split them into manageable chunks, and create a Chroma vector store with CohereEmbeddings for efficient document retrieval. We then initialize the Retriever with the path to our PDF data source, setting chunk size and overlap parameters for document processing.
def Retriever(folder_path,chunk_size=1200, chunk_overlap=200):
# Load documents from the specified folder
loader = PyPDFDirectoryLoader(folder_path)
documents = loader.load()
# Split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size , chunk_overlap=chunk_overlap)
chunks = text_splitter.split_documents(documents)
embeddings = CohereEmbeddings(model="embed-english-light-v3.0")
# Create a Chroma vector store from the document chunks and embeddings
db = Chroma.from_documents(chunks, embeddings)
return db.as_retriever()
# Initialize the Retriever with the path to your PDF data source
retriever = Retriever(file_name="your_data_source-folder",chunk_size=1200, chunk_overlap=200)
To verify that the Retriever is working correctly, we perform a test retrieval with a sample query to check if it returns relevant documents.
retriever.invoke("What is MOA ?")
Create The Router
from typing import Literal
from langchain_core.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain.output_parsers import StructuredOutputParser, PydanticOutputParser
We define a prompt and output parser to route a user query to the most relevant data source — either a vectorstore or web search.
# Data model
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasource: Literal["vectorstore", "websearch"] = Field(
...,
description="Given a user question choose to route it to web search or a vectorstore.",
)
# Output parser
routing_parser = PydanticOutputParser(pydantic_object=RouteQuery)
# Prompt
routing_system_template = """You are an expert at routing a user question to a vectorstore or websearch.
The vectorstore contains documents related to new AI Method called Mixture-of-Agents (MoA) .
Use the vectorstore for questions on these topics. For all else, use websearch."""
routing_system_message_prompt = SystemMessagePromptTemplate.from_template(routing_system_template)
routing_human_template = "{question}\n\n{format_instructions}"
routing_human_message_prompt = HumanMessagePromptTemplate.from_template(routing_human_template)
We start by creating a RouteQuery data model to specify the datasource for the question. We then set up a system prompt instructing the model to use the vectorstore for questions about the "Mixture-of-Agents" (MoA) method and web search for other topics.
# Combine prompts and add formatting instructions for structured output
chat_prompt = ChatPromptTemplate.from_messages(
[routing_system_message_prompt, routing_human_message_prompt]
)
# Format instructions for the LLM
routing_format_instructions = routing_parser.get_format_instructions()
# Create a chain to generate and parse the response
routing_chain = chat_prompt | llm | routing_parser
The routing_chain combines the prompts and applies the llm to generate and parse responses.
# Test the chain
print(routing_chain.invoke({"question": "What is MOA ? ", "format_instructions": routing_format_instructions}))
# output example
# datasource='vectorstore'
print(routing_chain.invoke({"question": "Who is Nikola tesla ?", "format_instructions": routing_format_instructions}))
# output example
# datasource='websearch'
Finally, can we test this chain with queries to ensure it correctly routes questions about Our Topic to the VectorStore and others to Web Search.
Create Grade Documents chain
We create a data model and a prompt setup to evaluate the relevance of retrieved documents to a user question.
First, we define a GradeDocuments data model with a binary score of "yes" or "no" to indicate if a document is relevant. The relevance_parser uses this model to parse the LLM’s responses.
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: Literal["yes", "no"] = Field(description="Documents are relevant to the question, 'yes' or 'no'")
# Output parser
relevance_parser = PydanticOutputParser(pydantic_object=GradeDocuments)
# System prompt
relevance_system_template = """You are a grader assessing relevance of a retrieved document to a user question.
If the document contains keyword(s) or semantic meaning related to the question, grade it as relevant.
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""
relevance_system_message_prompt = SystemMessagePromptTemplate.from_template(relevance_system_template)
# Human prompt
relevance_human_template = "Retrieved document: \n\n {document} \n\n User question: {question}\n\n{format_instructions}"
relevance_human_message_prompt = HumanMessagePromptTemplate.from_template(relevance_human_template)
# Combine prompts into a chat prompt template
chat_prompt = ChatPromptTemplate.from_messages(
[relevance_system_message_prompt, relevance_human_message_prompt]
)
We then construct a system prompt to guide the model in grading the relevance of documents based on their content and a user’s question. The relevance_human_template formats the actual document and question for the model. We combine these prompts into a chat_prompt template and create a retrieval_grader_relevance chain that uses llm to generate responses and relevance_parser to extract the binary relevance score.
# Format instructions for the LLM
retrieval_format_instructions = relevance_parser.get_format_instructions()
# Create a chain to generate and parse the response
retrieval_grader_relevance = chat_prompt | llm | relevance_parser
Finally, we test this chain with a sample question and document to verify that it correctly evaluates document relevance (optional).
# Example inputs (replace with actual retrieval and LLM instances)
question = "What is MOA ? "
docs = retriever.invoke(question) # Assuming `retriever` is your document retriever instance
doc_txt = docs[1].page_content # Access the content of the second retrieved document
# Test the chain
result = retrieval_grader_relevance.invoke({
"question": question,
"document": doc_txt,
"format_instructions": retrieval_format_instructions
})
print(result)
Create Grade Hallucinations chain
We start by creating the GradeHallucinations data model with a binary score of "yes" or "no" to indicate whether the generation is supported by the facts. The grader_parser uses this model to extract the LLM's response.
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: Literal["yes", "no"] = Field(...,description="Don't consider calling external APIs for additional information. Answer is supported by the facts, 'yes' or 'no'.")
# Output parser
grader_parser = PydanticOutputParser(pydantic_object=GradeHallucinations)
# System prompt
grader_system_template = """You are a grader assessing whether an LLM generation is supported by a set of retrieved facts.
Restrict yourself to give a binary score, either 'yes' or 'no'. If the answer is supported or partially supported by the set of facts, consider it a yes.
Don't consider calling external APIs for additional information as consistent with the facts."""
grader_system_message_prompt = SystemMessagePromptTemplate.from_template(grader_system_template)
# Human prompt
grader_human_template = "Set of facts: \n\n {documents} \n\n LLM generation: {generation}\n\n{format_instructions}"
grader_human_message_prompt = HumanMessagePromptTemplate.from_template(grader_human_template)
# Combine prompts into a chat prompt template
grader_chat_prompt = ChatPromptTemplate.from_messages(
[grader_system_message_prompt, grader_human_message_prompt]
)
# Format instructions for the LLM
grader_format_instructions = grader_parser.get_format_instructions()
# Create a chain to generate and parse the response
hallucination_grader = grader_chat_prompt | llm | grader_parser
We then establish a grader_system_template to instruct the model on how to assess if the response aligns with the provided facts, without considering additional external information. This is combined with a grader_human_template that formats the documents and the generation for evaluation. The grader_chat_prompt merges these into a ChatPromptTemplate, and we create the hallucination_grader chain to generate a response and parse it using grader_parser.
# Test the chain
result = hallucination_grader.invoke({
"documents": docs,
"generation": generation,
"format_instructions": grader_format_instructions
})
print(result)
Finally, we test this chain with example documents and a generation to ensure it correctly identifies any factual inaccuracies (optional) .
Create Grade Answer chain
The GradeAnswer data model uses a binary score of "yes" or "no" to assess if the answer resolves the question. The answer_grader_parser processes this model to extract the grading result.
class GradeAnswer(BaseModel):
"""Binary score to assess if the answer addresses the question."""
binary_score: Literal["yes", "no"] = Field(description="Answer addresses the question, 'yes' or 'no'")
# Output parser
answer_grader_parser = PydanticOutputParser(pydantic_object=GradeAnswer)
We craft a answer_grader_system_template that guides the model to evaluate if the provided answer addresses the question. This template is used in conjunction with the answer_grader_human_template to structure the user question and LLM response for the evaluation. Combining these, the chat_prompt creates a ChatPromptTemplate for the task. We then set up the answer_grader chain to generate the response and parse it using answer_grader_parser.
# System prompt
answer_grader_system_template = """You are a grader assessing whether an answer addresses / resolves a question.
Give a binary score 'yes' or 'no'. 'Yes' means that the answer resolves the question."""
answer_grader_system_message_prompt = SystemMessagePromptTemplate.from_template(answer_grader_system_template)
# Human prompt
answer_grader_human_template = "User question: \n\n {question} \n\n LLM generation: {generation}\n\n{format_instructions}"
answer_grader_human_message_prompt = HumanMessagePromptTemplate.from_template(answer_grader_human_template)
# Combine prompts into a chat prompt template
chat_prompt = ChatPromptTemplate.from_messages(
[answer_grader_system_message_prompt, answer_grader_human_message_prompt]
)
# Format instructions for the LLM
answer_format_instructions = answer_grader_parser.get_format_instructions()
# Create a chain to generate and parse the response
answer_grader = chat_prompt | llm | answer_grader_parser
Finally, we test the answer_grader chain with a sample question and answer to ensure it accurately determines if the answer resolves the question (optional) .
# Test the chain
result = answer_grader.invoke({
"question": question,
"generation": generation,
"format_instructions": answer_format_instructions
})
print(result)
Define search tool
from langchain_community.tools import DuckDuckGoSearchRun
duckduckgo_search = DuckDuckGoSearchRun()
We initialize the DuckDuckGoSearchRun tool to perform web searches using DuckDuckGo.
Create Generate chain
We set up a prompt and chain to generate concise answers based on retrieved context. The ChatPromptTemplate guides the LLM to answer the question in three sentences, and the StrOutputParser formats the response. We then run the chain with a sample question and context to get and print the answer.
from langchain_core.output_parsers import StrOutputParser
# Prompt
prompt = ChatPromptTemplate.from_template(
"""You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:"""
)
# Chain
rag_chain = prompt | llm | StrOutputParser()
Graph State
We define a GraphState class using TypedDict to represent the state of our graph with attributes for the question, LLM generation, web search flag, and a list of documents.
from typing_extensions import TypedDict
from langchain.schema import Document
from typing import List
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
web_search: whether to add search
documents: list of documents
"""
question : str
generation : str
web_search : str
documents : List[str]
Defining the Nodes
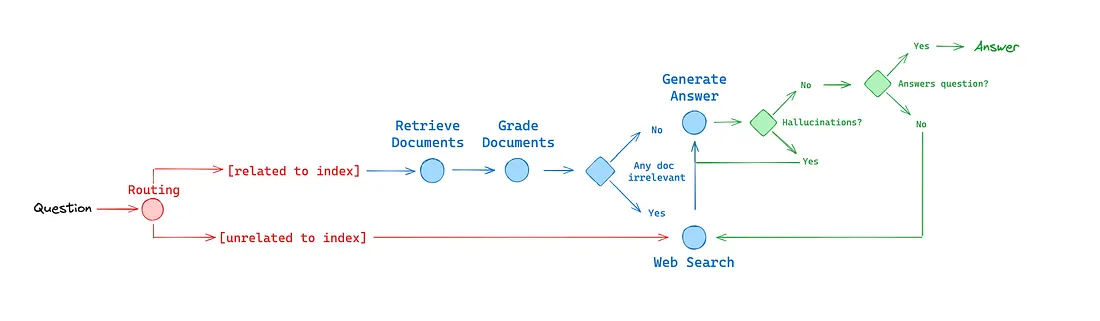
The route_question function determines whether to route the question to a web search or the RAG system based on the question's context. It uses a classification chain to decide the appropriate data source and directs the flow accordingly.
def route_question(state):
"""
Route question to web search or RAG
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
print("---ROUTE QUESTION---")
question = state["question"]
source = routing_chain.invoke({"question": question , "format_instructions" : routing_format_instructions})
if source.datasource == 'websearch':
print("---ROUTE QUESTION TO WEB SEARCH---")
return "websearch"
elif source.datasource == 'vectorstore':
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"
The retrieve function queries the vector store database to fetch documents based on the user’s question and updates the state with the retrieved documents.
def retrieve(state):
"""
Retrieve documents from vectorstore
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE from Vector Store DB---")
question = state["question"]
# Retrieval
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
The grade_documents function evaluates the relevance of retrieved documents to the user’s question. It filters out irrelevant documents and sets a flag to trigger a web search if any documents are deemed not relevant.
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question
If any document is not relevant, we will set a flag to run web search
Args:
state (dict): The current graph state
Returns:
state (dict): Filtered out irrelevant documents and updated web_search state
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
web_search = "No"
for d in documents:
score = retrieval_grader_relevance.invoke({"question": question, "document": d.page_content , "format_instructions" : retrieval_format_instructions})
grade = score.binary_score
# Document relevant
if grade.lower() == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
# Document not relevant
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
# We do not include the document in filtered_docs
# We set a flag to indicate that we want to run web search
web_search = "Yes"
continue
return {"documents": filtered_docs, "question": question, "web_search": web_search}
The web_search function performs a web search using DuckDuckGo and appends the search results to the existing documents. It updates the state with the new set of documents, including the web search results.
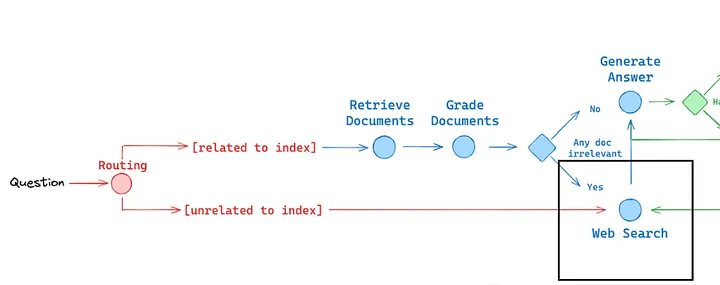
def web_search(state):
"""
Web search based based on the question
Args:
state (dict): The current graph state
Returns:
state (dict): Appended web results to documents
"""
print("---WEB SEARCH. Append to vector store db---")
question = state["question"]
documents = state["documents"]
# Web search
docs = duckduckgo_search.invoke({"query": question})
web_results = Document(page_content=docs)
if documents is not None:
documents.append(web_results)
else:
documents = [web_results]
return {"documents": documents, "question": question}
The decide_to_generate function checks if any documents are deemed relevant based on the web search flag. If the flag indicates that web search is needed, it routes to the websearch node; otherwise, it proceeds to the generate node for producing an answer.
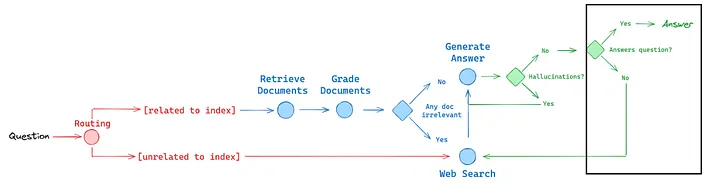
def decide_to_generate(state):
"""
Determines whether to generate an answer, or add web search
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
question = state["question"]
web_search = state["web_search"]
filtered_documents = state["documents"]
if web_search == "Yes":
# All documents have been filtered check_relevance
# We will re-generate a new query
print("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, INCLUDE WEB SEARCH---")
return "websearch"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
The grade_generation_v_documents_and_question function evaluates the LLM generation for both factual accuracy and relevance to the question. It first checks for hallucinations and then verifies if the generation addresses the question. Based on these checks, it decides whether the generation is useful or needs to be re-tried.
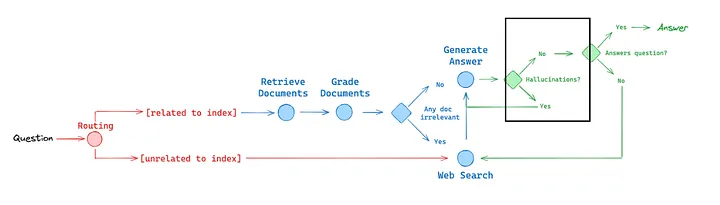
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke({"documents": documents, "generation": generation , "format_instructions" : grader_format_instructions})
grade = score.binary_score
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question,"generation": generation , "format_instructions" : answer_format_instructions})
grade = score.binary_score
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
print("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"
Define the nodes and build the graph
The StateGraph object is configured to manage the workflow of the RAG pipeline. Nodes are defined for web search, document retrieval, document grading, and answer generation. Conditional edges are set to route questions, decide between web search and generation, and evaluate the LLM's response. Finally, the graph is compiled to create the workflow application.
from langgraph.graph import END, StateGraph
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("websearch", web_search) # web search # key: action to do
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_edge("websearch", "generate") #start -> end of node
workflow.add_edge("retrieve", "grade_documents")
# Build graph
workflow.set_conditional_entry_point(
route_question,
{
"websearch": "websearch",
"vectorstore": "retrieve",
},
)
workflow.add_conditional_edges(
"grade_documents", # start: node
decide_to_generate, # defined function
{
"websearch": "websearch", #returns of the function
"generate": "generate", #returns of the function
},
)
workflow.add_conditional_edges(
"generate", # start: node
grade_generation_v_documents_and_question, # defined function
{
"not supported": "generate", #returns of the function
"useful": END, #returns of the function
"not useful": "websearch", #returns of the function
},
)
# Compile
app = workflow.compile()
Run Examples
The app.stream method processes the input through the state graph and prints out the progress of each node. Finally, the answer generated by the pipeline is printed.
First Example
from pprint import pprint
inputs = {"question": "what is Mixture-of-Agents (MoA) ? "}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Finished running: {key}:")
pprint(value["generation"])
Output :
---ROUTE QUESTION---
---ROUTE QUESTION TO RAG---
---RETRIEVE from Vector Store DB---
'Finished running: retrieve:'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
'Finished running: grade_documents:'
---GENERATE Answer---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
'Finished running: generate:'
('Mixture-of-Agents (MoA) is a methodology that utilizes multiple LLMs to '
'iteratively synthesize and refine responses, improving overall output '
'quality. MoA enhances collaborative potential by introducing additional '
'aggregators to build upon outputs from other models. This approach has shown '
'substantial improvements in response quality over relying on a single model.')
Second Example
from pprint import pprint
inputs = {"question": "Who is barak obama ?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Finished running: {key}:")
pprint(value["generation"])
Output :
---ROUTE QUESTION---
---ROUTE QUESTION TO WEB SEARCH---
---WEB SEARCH. Append to vector store db---
'Finished running: websearch:'
---GENERATE Answer---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
'Finished running: generate:'
('Barack Obama was the 44th President of the United States, serving from 2009 '
'to 2017. He was the first African American to hold this office and is known '
'for his charismatic personality and focus on political change. Obama '
'previously served in the Illinois Senate and is the son of a Kenyan father '
'and a white mother.')