Building Advanced Retrieval-Augmented Generation (RAG) Apps with NVIDIA NIM
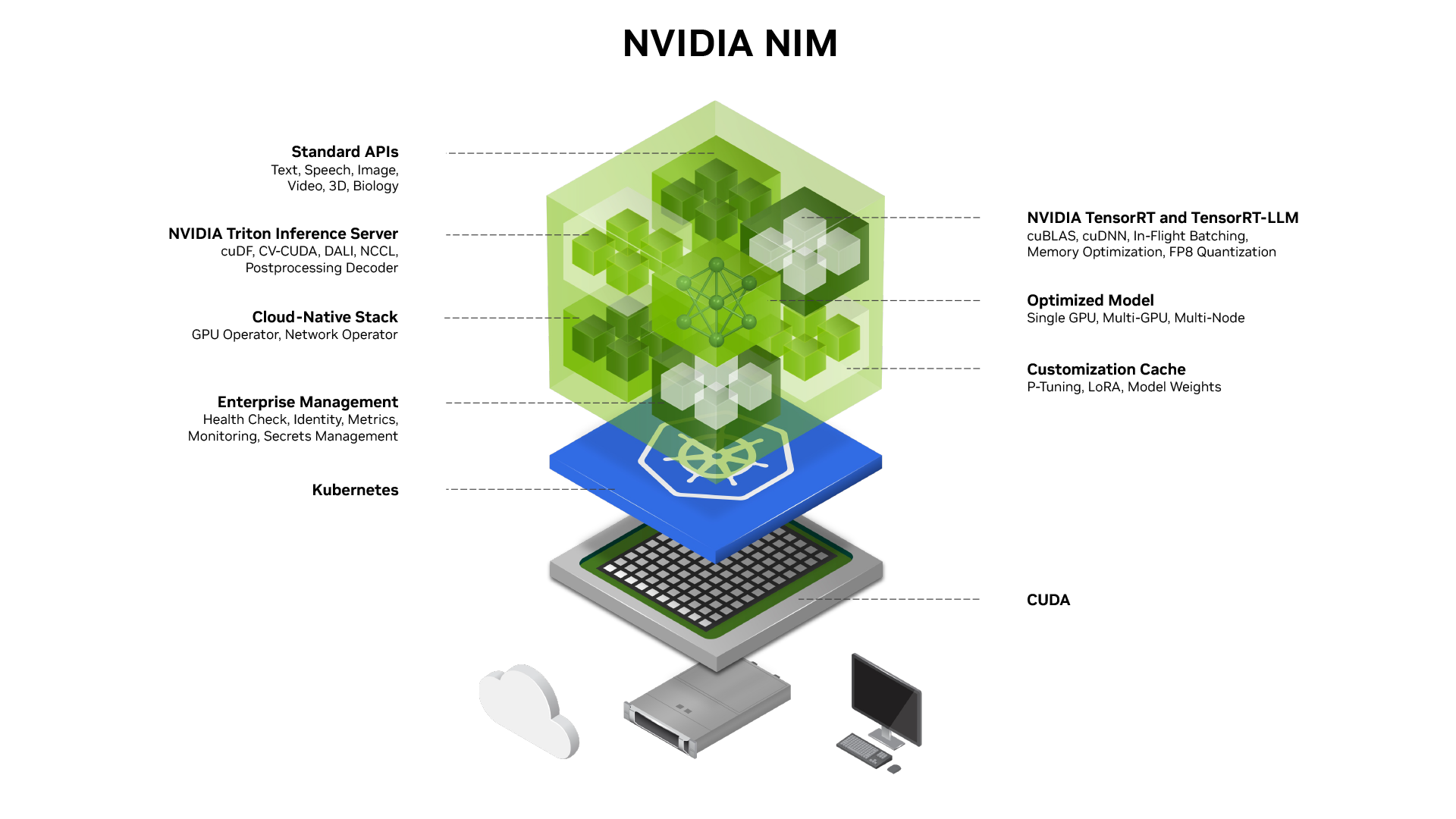
Retrieval-Augmented Generation (RAG) has emerged as a powerful approach for enhancing AI applications, particularly in contexts where accessing and synthesizing large volumes of information is critical. By combining retrieval techniques with large language models (LLMs), RAG systems can deliver more accurate and contextually relevant responses. In this post, we will explore how to build a state-of-the-art RAG application using NVIDIA NIM, focusing on the NV-Embed-QA model, Meta's LLaMA 3.1-405B-Instruct, and NVIDIA's NVIDIARerank. Additionally, we will leverage the Sub Question Query Engine from the Llama-Index framework to refine our retrieval process.
1. NV-Embed-QA Model: Embedding for Enhanced Retrieval
At the core of our RAG system is the NV-Embed-QA model, hosted on NVIDIA NIM. This model is optimized for embedding textual information into dense vector representations. Embedding models are crucial in retrieval systems because they transform raw text into a form that can be efficiently compared and searched.
The NV-Embed-QA model employs advanced transformer architectures to create embeddings that capture the semantic meaning of text. By converting documents, queries, and other textual data into high-dimensional vectors, this model enables us to perform semantic searches with high accuracy. When a user query is processed, it is converted into an embedding that is then compared against the embeddings of stored documents to find the most relevant information.
2. Meta LLaMA 3.1-405B-Instruct: Powerful Language Generation
For generating contextually relevant and coherent responses, we utilize the Meta LLaMA 3.1-405B-Instruct model, also hosted on NVIDIA NIM. This model stands out due to its size (405 billion parameters) and its instruction-tuned nature, which enhances its performance on dialogue and question-answering tasks.
The LLaMA 3.1 model uses an auto-regressive transformer architecture, meaning it generates text one token at a time based on the previous tokens. With its instruction-tuning and reinforcement learning with human feedback (RLHF), this model is optimized to align closely with human preferences, providing responses that are both accurate and contextually appropriate.
3. NVIDIARerank: Enhancing Retrieval Accuracy
To refine the retrieval process and ensure that the most relevant results are presented, we integrate the NVIDIARerank model. This model is designed to re-rank the retrieved passages, improving the quality of the results based on additional relevance scoring. Reranking is a critical step in high-accuracy retrieval pipelines, as it enhances the precision of the results by adjusting the ranking based on more nuanced criteria.
NVIDIARerank takes the initial set of retrieved documents and applies a sophisticated ranking algorithm to reorder them based on their relevance to the query. This ensures that the top results are the most pertinent, improving the overall quality of the responses generated by the system.
4. Sub Question Query Engine: Breaking Down Queries for Better Answers
An innovative component of our RAG system is the Sub Question Query Engine from the Llama-Index framework. This engine improves the effectiveness of retrieval by breaking down a complex query into smaller, more manageable sub-questions. Each sub-question is directed to a relevant data source, and the intermediate answers are aggregated to form a comprehensive response to the original query.
This approach is particularly useful in scenarios where the user query is multifaceted or involves multiple aspects of a subject. By dissecting the query and retrieving specific pieces of information, the Sub Question Query Engine helps in providing a more detailed and accurate answer, leveraging various data sources for a richer response.
Code Example
Installing Requirements
To set up your environment :
pip install --upgrade pip
pip install llama-index
pip install llama-index-core==0.10.50
pip install llama-index-readers-file==0.1.25
pip install llama-index-llms-nvidia==0.1.3
pip install llama-index-embeddings-nvidia==0.1.4
pip install llama-index-postprocessor-nvidia-rerank==0.1.2
pip install ipywidgets==8.1.3
Importing Dependencies :
from llama_index.postprocessor.nvidia_rerank import NVIDIARerank
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.core.query_engine import SubQuestionQueryEngine
from llama_index.embeddings.nvidia import NVIDIAEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import SimpleDirectoryReader
from llama_index.core import VectorStoreIndex
from llama_index.llms.nvidia import NVIDIA
from llama_index.core import Settings
import nest_asyncio
import os
If you are working in a Jupyter notebook, apply nest_asyncio to ensure proper handling of asynchronous code execution. This step is crucial for running asynchronous operations in notebook environments where asyncio might otherwise be restricted.
nest_asyncio.apply()
Setting the NVIDIA API Key :
Assign your NVIDIA API key to the NVIDIA_API_KEY environment variable. This key is required for authenticating API requests to NVIDIA services.
nvidia_api_key = "nvapi-xxxxxxxxxxxxxxx"
os.environ["NVIDIA_API_KEY"] = nvidia_api_key
Ensure you replace "nvapi-xxxxxxxxxxxxxxx" with your actual API key.
Configuring Models :
Set up the embedding and LLM models using the Settings class. For embeddings, configure NVIDIAEmbedding with the NV-Embed-QA model, specifying truncate="END" to handle text truncation.
Settings.embed_model = NVIDIAEmbedding(model="NV-Embed-QA", truncate="END")
Settings.llm = NVIDIA(model="meta/llama-3.1-405b-instruct")
For the LLM, use NVIDIA with the meta/llama-3.1-405b-instruct model, which provides advanced instruction-tuned capabilities.
Loading Data :
Specify the path to your data folder and use SimpleDirectoryReader to load your documents.
DATA_PATH = "data"
Settings.text_splitter = SentenceSplitter()
documents = SimpleDirectoryReader(DATA_PATH).load_data()
Apply SentenceSplitter to handle text segmentation. This setup ensures that your documents are appropriately prepared for indexing and querying.
Indexing Documents and Creating a Query Engine:
Create a vector store index from your documents using VectorStoreIndex, enabling asynchronous operations for efficiency.
index = VectorStoreIndex.from_documents(documents , use_async=True)
vector_query_engine = index.as_query_engine(
similarity_top_k=40, node_postprocessors=[NVIDIARerank(top_n=4)]
)
Instantiate a base query engine with the index, incorporating NVIDIARerank for improved result ranking. The similarity_top_k parameter controls the number of top documents considered during querying, while top_n specifies how many results are retained after reranking.
Creating a Sub Question Query Engine:
Build a SubQuestionQueryEngine using the base query engine. Define QueryEngineTool instances with relevant metadata to describe the tool’s purpose. The description should be detailed and contextually appropriate to the documents' topics, enhancing the relevance and clarity of the sub-questions generated.
query_engine_tools = [
QueryEngineTool(
query_engine=vector_query_engine,
metadata=ToolMetadata(
name="QA",
description=".... write the tool descreption...",
),
),
]
Sub_query_engine = SubQuestionQueryEngine.from_defaults(
query_engine_tools=query_engine_tools,
use_async=True,
)
Use the SubQuestionQueryEngine.from_defaults method to set up this engine for processing sub-queries asynchronously.
Query Time:
Execute queries against the configured query engine by invoking the query method. Pass your question as a string to retrieve the relevant response based on the indexed documents.
response = query_engine.query(
".. ask your question here .."
)
print(response)
Print the response to view the results.
Building a Retrieval-Augmented Generation (RAG) system with NVIDIA NIM and its technologies offers a substantial boost in speed and latency for AI applications. Utilizing the NV-Embed-QA model for embeddings, Meta LLaMA 3.1-405B-Instruct for generation, and NVIDIARerank for refined retrieval, combined with the Sub Question Query Engine, ensures swift and accurate responses. This setup not only enhances the precision of answers but also effectively handles complex queries and diverse data sources, paving the way for next-generation enterprise solutions.