Getting Started With Parler-TTS

The Parler-TTS project is excited to announce the release of two new text-to-speech models!
First up, we have Parler-TTS Mini v0.1, a lightweight model perfect for quick and easy speech generation. Inspired by recent research Natural Language Guidance of High-Fidelity Text-to-Speech with Synthetic Annotations paper, Parler-TTS Mini v0.1 gives you intuitive control over various speech aspects like gender, background noise, and speaking rate, all through a simple text prompt. You can find it here: https://huggingface.co/parler-tts/parler_tts_mini_v0.1.
For those looking for maximum expressiveness and control, we also have Parler-TTS Large v1. Trained on a massive 45K hours of audio data, this 2.2B-parameter model delivers truly high-quality, natural-sounding speech with extensive control over a wide range of features, including gender, background noise, speaking rate, pitch, and reverberation. Check it out at: https://huggingface.co/parler-tts/parler-tts-large-v1.
Natural language guidance of high-fidelity text-to-speech with synthetic annotations paper presents a novel text-to-speech (TTS) system that achieves high-fidelity and diverse speech generation by leveraging large-scale datasets and natural language descriptions.
Motivation: Existing TTS systems often rely on reference audio for controlling speaker identity and style, limiting their creative applications. While natural language prompting offers a more intuitive solution, previous attempts were constrained by the lack of large-scale datasets with detailed natural language descriptions of speech attributes.
Key Contributions:
-
Automatic Labeling: The authors address the data scarcity problem by proposing a scalable method for automatically labeling a massive 45k-hour speech dataset (Multilingual LibriSpeech) with various attributes like gender, accent, speaking rate, pitch, and recording quality. They also include a smaller high-fidelity dataset (LibriTTS-R) to improve audio quality.
-
Speech Language Model: This labeled dataset is used to train a speech language model adapted from AudioCraft, a general-purpose audio generation library. The model architecture uses a decoder-only Transformer network. Unlike previous work, this model relies solely on natural language descriptions for controlling speech attributes, without any reference audio embeddings.
-
High-Fidelity Audio: The system utilizes the Descript Audio Codec (DAC) for generating high-fidelity audio, achieving significant improvements over previous methods, even with limited high-fidelity training data.
Model Architecture:
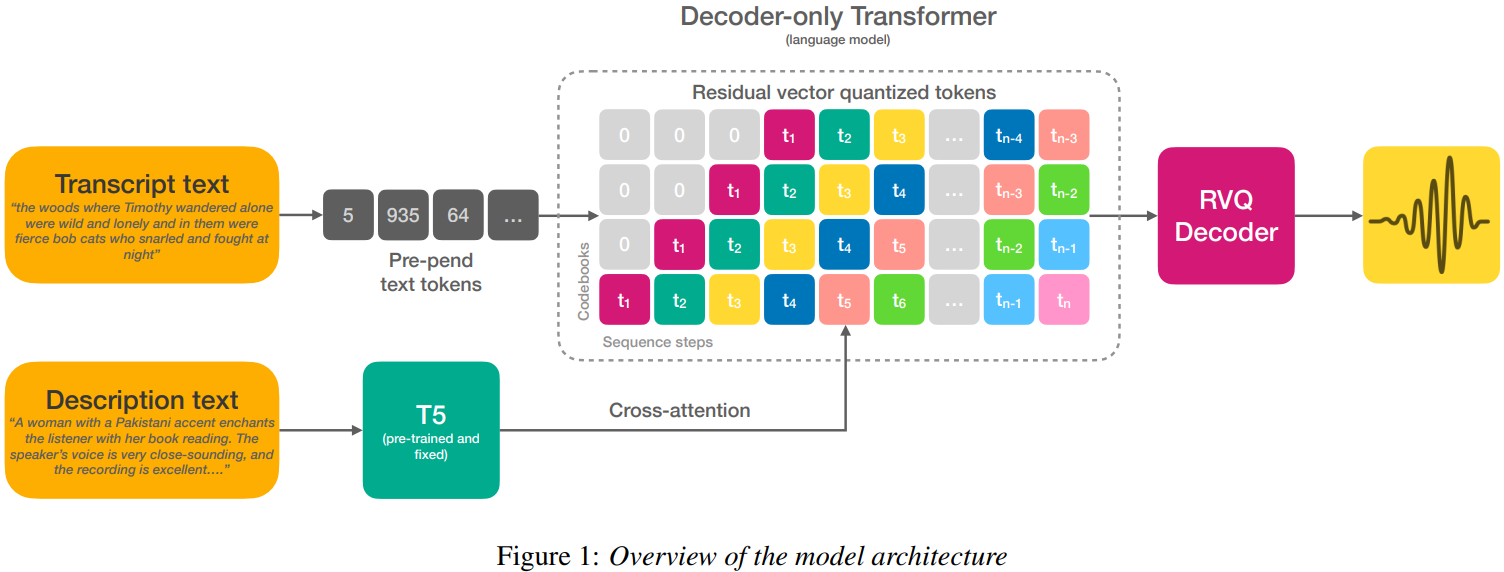
The TTS system employs a decoder-only Transformer architecture. The input consists of:
- Transcript text: The text to be synthesized, pre-pended to the input sequence.
- Description text: Natural language descriptions of desired speech characteristics (e.g., "A man with a British accent speaking in a lively tone"). This is processed by a pre-trained T5 text encoder and fed to the decoder through cross-attention.
The output of the decoder is a sequence of discrete tokens representing audio features, which are then converted to audio waveforms using the DAC decoder.
Training:
The model is trained on the large-scale labeled dataset. The training process involves optimizing the model to generate speech that accurately matches the provided text transcript and description.
Evaluation:
The system is evaluated using both objective and subjective measures:
- Objective Evaluation: Accuracy of gender and accent classification, correlation between synthesized and described attributes, and audio fidelity metrics (PESQ, STOI, SI-SDR).
- Subjective Evaluation: Listening tests to evaluate the relevance of generated speech to the descriptions (REL) and the overall naturalness (MOS).
Results:
The results demonstrate that this system can generate high-fidelity speech with a wide range of accents, prosodic styles, and recording conditions, controlled by intuitive natural language descriptions. It outperforms concurrent work in terms of both audio fidelity and the accuracy of matching the descriptions.
1 / Inference
Setting up Parler-TTS
First, install the Parler-TTS package.
! pip install git+https://github.com/huggingface/parler-tts.git
And import the necessary modules
import torch
from parler_tts import ParlerTTSForConditionalGeneration, ParlerTTSStreamer
from transformers import AutoTokenizer
from threading import Thread
import soundfile as sf
Then set your preferred torch_device, torch_dtype, and model_name. we also set a max_length for padding and load the pre-trained model and tokenizer. lastly we grab the sampling rate and frame rate from the model configuration.
torch_device = "cuda:0" # Use "mps" for Mac
torch_dtype = torch.bfloat16
model_name = "parler-tts/parler-tts-mini-v1"
# need to set padding max length
max_length = 50
# load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = ParlerTTSForConditionalGeneration.from_pretrained(
model_name,
).to(torch_device, dtype=torch_dtype)
sampling_rate = model.audio_encoder.config.sampling_rate
frame_rate = model.audio_encoder.config.frame_rate
Generating Speech with a Random Voice
Now, let's generate some speech.. Provide a text prompt and a description of the desired voice and speaking style. The description is tokenized and fed into the model, which generates the corresponding audio. You can then listen to the generated audio directly in your notebook. Check here.
from IPython.display import Audio
prompt = "Hey, how are you doing today?"
description = "A female speaker delivers a slightly expressive and animated speech with a moderate speed and pitch. The recording is of very high quality, with the speaker's voice sounding clear and very close up."
input_ids = tokenizer(description, return_tensors="pt").input_ids.to(torch_device)
prompt_input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(torch_device)
generation = model.generate(input_ids=input_ids, prompt_input_ids=prompt_input_ids)
audio_arr = generation.cpu().float().numpy().squeeze()
Audio(audio_arr, rate=model.config.sampling_rate)
Generating Speech with a Specific Speaker
You can also guide the model to generate speech that resembles a particular speaker. Simply include the speaker's name or a descriptive phrase in your description, along with desired characteristics.
prompt = "Hey, how are you doing today?"
description = "Jon's voice is monotone yet slightly fast in delivery, with a very close recording that almost has no background noise."
input_ids = tokenizer(description, return_tensors="pt").input_ids.to(torch_device)
prompt_input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(torch_device)
generation = model.generate(input_ids=input_ids, prompt_input_ids=prompt_input_ids)
audio_arr = generation.cpu().float().numpy().squeeze()
Audio(audio_arr, rate=model.config.sampling_rate)
You can select from 34 pre-defined speaker names and tailor their speech style with your descriptions(e.g. Jon, Lea, Gary, Jenna, Mike, Laura) .
Tips:
- Include the term "very clear audio" to generate the highest quality audio, and "very noisy audio" for high levels of background noise .
- Punctuation can be used to control the prosody of the generations, e.g. use commas to add small breaks in speech.
- The remaining speech features (gender, speaking rate, pitch and reverberation) can be controlled directly through the prompt.
Streaming Speech Generation
For longer text inputs, stream the audio output in chunks. This allows you to hear the generated speech as it's being created, offering a more interactive experience.
def generate(text, description, play_steps_in_s=0.5):
play_steps = int(frame_rate * play_steps_in_s)
streamer = ParlerTTSStreamer(model, device=torch_device, play_steps=play_steps)
# tokenization
inputs = tokenizer(description, return_tensors="pt").to(torch_device)
prompt = tokenizer(text, return_tensors="pt").to(torch_device)
# create generation kwargs
generation_kwargs = dict(
input_ids=inputs.input_ids,
prompt_input_ids=prompt.input_ids,
attention_mask=inputs.attention_mask,
prompt_attention_mask=prompt.attention_mask,
streamer=streamer,
do_sample=True,
temperature=1.0,
min_new_tokens=10,
)
# initialize Thread
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
# iterate over chunks of audio
for new_audio in streamer:
if new_audio.shape[0] == 0:
break
yield sampling_rate, new_audio
text = "Parler-TTS is an auto-regressive transformer-based model, meaning generates audio codes (tokens) in a causal fashion."
description = "Mike's talking really fast."
chunk_size_in_s = 0.5
for (sampling_rate, audio_chunk) in generate(text, description, chunk_size_in_s):
display(Audio(audio_chunk, rate=sampling_rate))
2 / Fine-tuning
This guide demonstrates the process of fine-tuning a Parler-TTS model on a single-speaker dataset. For a complete walkthrough and code implementation, refer to the full notebook available here.
Before running the notebook, ensure you have the necessary dependencies installed by executing the following commands:
1. Install DataSpeech:
!git clone https://github.com/huggingface/dataspeech.git
!cd dataspeech
!pip install --quiet -r ./dataspeech/requirements.txt
2. Install Parler-TTS:
!git clone https://github.com/huggingface/parler-tts.git
%cd parler-tts
!pip install --quiet -e .[train]
3. Install Additional Dependencies:
!pip install --upgrade protobuf wandb==0.16.6
4. Login to Hugging Face:
!git config --global credential.helper store
!huggingface-cli login
1. Creating our fine-tuning dataset
This section aims to create an annotated version of the Jenny TTS dataset for fine-tuning the Parler-TTS v0.1 checkpoint. The full dataset is available on the Hugging Face Hub as reach-vb/jenny_tts_dataset, inspired by the Data-Speech FAQ.
For demonstration purposes, this notebook uses a 6-hour subset: ylacombe/jenny-tts-6h. You can listen to samples via the Hub viewer.
The process involves: 1) annotating the dataset with continuous variables measuring speech characteristics (speaking rate, SNR, reverberation, and speech monotony), 2) mapping these annotations to descriptive text bins, and 3) creating natural language descriptions from these bins.
The annotation process utilizes main.py to extract the continuous variables.
For a more detailed explanation, refer to the Data-Speech README.
%cd ../dataspeech
!python main.py "ylacombe/jenny-tts-6h" \
--configuration "default" \
--text_column_name "transcription" \
--audio_column_name "audio" \
--cpu_num_workers 2 \
--num_workers_per_gpu_for_pitch 2 \
--rename_column \
--repo_id "jenny-tts-tags-6h"
2. Map annotations to text bins
To maintain consistency with the training data of the Parler-TTS v0.1 checkpoint, we'll utilize the same text bins for the Jenny dataset. This is achieved using the following command:
!python ./scripts/metadata_to_text.py \
"ylacombe/jenny-tts-tags-6h" \
--repo_id "jenny-tts-tags-6h" \
--configuration "default" \
--cpu_num_workers 2 \
--path_to_bin_edges "./examples/tags_to_annotations/v01_bin_edges.json" \
--avoid_pitch_computation
This script ensures compatibility between the Jenny dataset and the Parler-TTS model by applying the same text binning process used during the model's initial training.
3. Create natural language descriptions from those text bins
Having assigned text bins to the Jenny dataset, the next step involves generating natural language descriptions based on these features. Our chosen approach is to create prompts that incorporate the name "Jenny" and describe the speech characteristics, resulting in prompts like: "In a very expressive voice, Jenny pronounces her words incredibly slowly. There's some background noise in this room with a bit of echo."
This resource-intensive step typically requires GPU utilization. The following command demonstrates this process using the 2B version of the Gemma model from Google, which should complete in approximately 15 minutes on a Colab free T4.
!python ./scripts/run_prompt_creation.py \
--speaker_name "Jenny" \
--is_single_speaker \
--dataset_name "ylacombe/jenny-tts-tags-6h" \
--output_dir "./tmp_jenny" \
--dataset_config_name "default" \
--model_name_or_path "google/gemma-2b-it" \
--per_device_eval_batch_size 12 \
--attn_implementation "sdpa" \
--dataloader_num_workers 2 \
--push_to_hub \
--hub_dataset_id "jenny-tts-6h-tagged" \
--preprocessing_num_workers 2
The command specifies the dataset and configuration to annotate. The model_name_or_path argument points to a suitable transformers model for prompt annotation, with a list of options available here.
Notably, the flags --speaker_name "Jenny" --is_single_speaker explicitly define the dataset as mono-speaker and identify the voice as "Jenny."
Start Fine-tuning Parler-TTS
With the annotated Jenny dataset ready, we can now focus on fine-tuning the Parler-TTS model. The Parler-TTS library provides a convenient training script here that simplifies this process.
Note: The script requires a decision regarding Weights & Biases (WandB) logging. If you lack an account, choose option 3 to disable logging. Otherwise, enable logging to track your model's training progress.
The following command initiates the fine-tuning process:
%cd ../parler-tts
!accelerate launch ./training/run_parler_tts_training.py \
--model_name_or_path "parler-tts/parler_tts_mini_v0.1" \
--feature_extractor_name "parler-tts/dac_44khZ_8kbps" \
--description_tokenizer_name "parler-tts/parler_tts_mini_v0.1" \
--prompt_tokenizer_name "parler-tts/parler_tts_mini_v0.1" \
--report_to "wandb" \
--overwrite_output_dir true \
--train_dataset_name "ylacombe/jenny-tts-6h" \
--train_metadata_dataset_name "ylacombe/jenny-tts-6h-tagged" \
--train_dataset_config_name "default" \
--train_split_name "train" \
--eval_dataset_name "ylacombe/jenny-tts-6h" \
--eval_metadata_dataset_name "ylacombe/jenny-tts-6h-tagged" \
--eval_dataset_config_name "default" \
--eval_split_name "train" \
--max_eval_samples 8 \
--per_device_eval_batch_size 8 \
--target_audio_column_name "audio" \
--description_column_name "text_description" \
--prompt_column_name "text" \
--max_duration_in_seconds 20 \
--min_duration_in_seconds 2.0 \
--max_text_length 400 \
--preprocessing_num_workers 2 \
--do_train true \
--num_train_epochs 2 \
--gradient_accumulation_steps 18 \
--gradient_checkpointing true \
--per_device_train_batch_size 2 \
--learning_rate 0.00008 \
--adam_beta1 0.9 \
--adam_beta2 0.99 \
--weight_decay 0.01 \
--lr_scheduler_type "constant_with_warmup" \
--warmup_steps 50 \
--logging_steps 2 \
--freeze_text_encoder true \
--audio_encoder_per_device_batch_size 4 \
--dtype "float16" \
--seed 456 \
--output_dir "./output_dir_training/" \
--temporary_save_to_disk "./audio_code_tmp/" \
--save_to_disk "./tmp_dataset_audio/" \
--dataloader_num_workers 2 \
--do_eval \
--predict_with_generate \
--include_inputs_for_metrics \
--group_by_length true
This script leverages the annotated Jenny dataset and specified parameters to fine-tune the Parler-TTS model, ultimately enhancing its performance and tailoring it to the characteristics of the Jenny voice.