ColPali: Efficient Document Retrieval with Vision Language Models
Retrieval-Augmented Generation (RAG) is a sophisticated framework that combines information retrieval with natural language generation to enhance the output of AI models. Unlike traditional models that rely solely on pre-trained knowledge, RAG dynamically retrieves relevant information from external sources to augment the input before generating a response. This approach is particularly useful in scenarios where the model needs to answer queries or generate text based on up-to-date or domain-specific information, making it more accurate and contextually relevant.
Introduction to ColPali
ColPali is an innovative system designed to improve document retrieval by leveraging the capabilities of vision language models. Traditional document retrieval methods typically depend on text extraction through Optical Character Recognition (OCR) and subsequent analysis, which can miss important visual information such as layout, images, and fonts. ColPali addresses these shortcomings by directly using images of document pages to create embeddings that encapsulate both textual and visual information. This enables more effective retrieval and understanding of documents that are rich in visual content.
Theoretical Background
RAG Basics
RAG operates on a three-step process: retrieval, augmentation, and generation. Here’s a breakdown of each step:
Retrieval: Given a query or prompt, the system first retrieves relevant documents or information from a knowledge base. This step is crucial for providing contextually appropriate data to the model.
Augmentation: The retrieved information is then used to enhance or augment the original input. This could involve integrating additional facts, context, or details that are pertinent to the query.
Generation: Finally the augmented input is fed into a language model to generate the output, such as a detailed answer or a piece of text that reflects the combined knowledge from both the query and the retrieved information.
ColPali Architecture
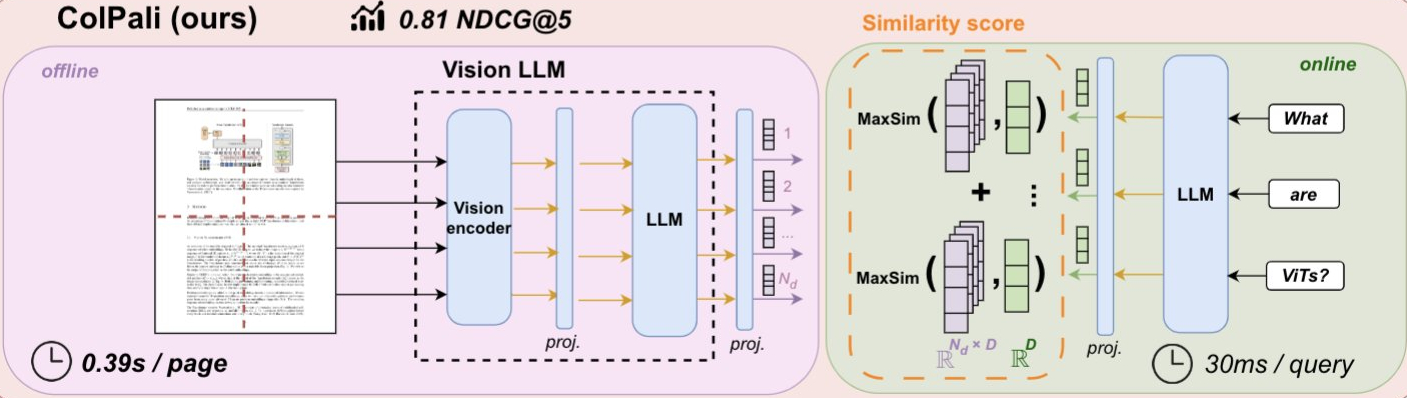
ColPali stands out by utilizing a vision language model to process and understand documents.
The architecture can be broken down into several components:
-
Vision Transformer (SigLIP-So400m): This model processes the images of document pages, converting them into meaningful visual embeddings.
-
PaliGemma-3B: A large vision language model that takes the visual embeddings and generates high-quality contextualized representations of the documents.
-
Late Interaction Mechanism: Similar to the
ColBERTapproach, this mechanism allows for fine-grained matching between query tokens and document patches , it ensures that the retrieval process is both precise and contextually rich.
Comparison with Traditional Systems
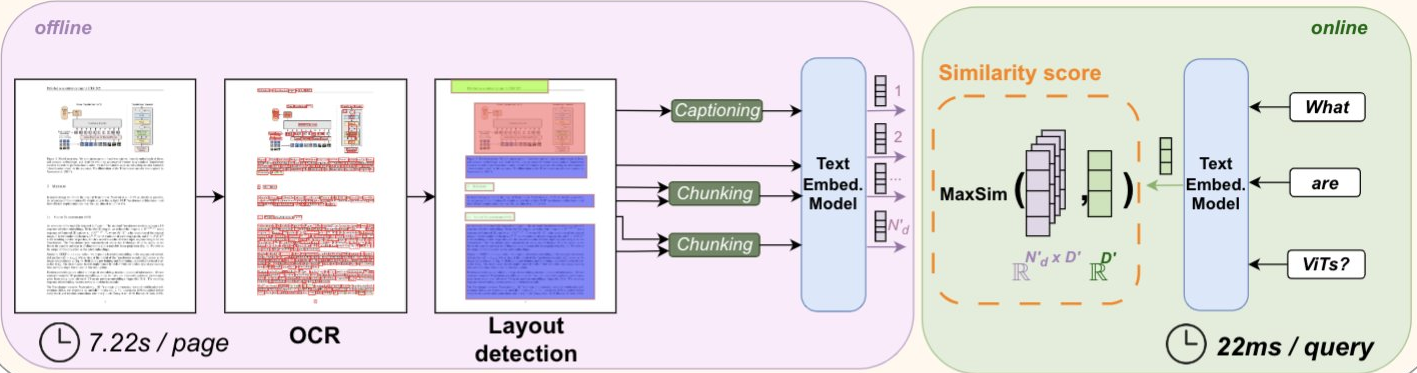
Traditional document retrieval systems primarily rely on OCR to convert scanned documents into text, followed by text-based retrieval techniques , these methods often lose vital visual information embedded in the document layout, images, and formatting. ColPali bypasses this limitation by directly working with the document images, preserving the visual context and thereby improving retrieval accuracy and efficiency. This approach not only enhances performance but also speeds up the indexing process, making it more suitable for practical applications where visual elements are critical.
By integrating advanced vision language models with retrieval-augmented generation, ColPali represents a significant leap forward in the field of document understanding and retrieval , it offers a robust solution for handling visually rich documents, making it a valuable tool for various domains requiring accurate and contextually relevant information extraction.
In this project we will use ColPali as a retrieval model, leveraging its advanced capabilities for handling visually rich documents , for the generation component, we will use Gemini-1.5-Flash to produce contextually relevant responses. Additionally, we will develop a straightforward user interface with Gradio, allowing users to input text, receive responses, and view the source images associated with the retrieved documents.
Code Time
Install dependencies
Before we can proceed, we need to install the necessary dependencies.
! pip install git+https://github.com/illuin-tech/colpali
! pip install pdf2image einops google-generativeai gradio
! apt-get install poppler-utils
Login to Hugging Face
This command logs you into your Hugging Face account via the command line. It uses the --token flag to provide your authentication token, allowing access to download and use models from Hugging Face’s hub.
! huggingface-cli login --token xxxxxxxxxxxxxxxx
Importing Libraries
Here We import the necessary libraries.
import torch
import typer
from tqdm import tqdm
from transformers import AutoProcessor
from PIL import Image
from torch.utils.data import DataLoader
from pdf2image import convert_from_path
from colpali_engine.models.paligemma_colbert_architecture import ColPali
from colpali_engine.trainer.retrieval_evaluator import CustomEvaluator
from colpali_engine.utils.colpali_processing_utils import process_images, process_queries
Load ColPali model as a Retrieval
We load the paligemma-3b-mix-448 model and we adapt it with vidore/colpali adapter.
model_name = "vidore/colpali" # specify the adapter model name
retrieval_model = ColPali.from_pretrained("google/paligemma-3b-mix-448",
torch_dtype=torch.bfloat16, # set the dtype to bfloat16 (you can also use float32)
device_map="cuda").eval() # set the device to cuda
retrieval_model.load_adapter(model_name)
processor = AutoProcessor.from_pretrained(model_name)
device = retrieval_model.device
Indexing Documents
This function indexes PDF documents by converting each page into an image and then generating embeddings for these images using our pre-trained retrieval model, the function takes a list of PDF file paths, converts each page of these PDFs into images, and stores them in a list , these images are then processed in batches using a DataLoader, which helps manage the data in an efficient and organized manner , for each batch of images the function leverages a processor to prepare the images for the model and during the inference phase it uses the retrieval model to generate embeddings for each page of course without updating the model's weights.
# Function to index the PDF document (Get the embedding of each page)
def index(files: List[str]) -> Tuple[str, List[torch.Tensor], List[Image.Image]]:
images = []
document_embeddings = []
# Convert PDF pages to images
for file in files:
images.extend(convert_from_path(file))
# Create DataLoader for image batches
dataloader = DataLoader(
images,
batch_size=4,
shuffle=False,
collate_fn=lambda x: process_images(processor, x),
)
# Process each batch and obtain embeddings
for batch in dataloader:
with torch.no_grad():
batch = {key: value.to(device) for key, value in batch.items()}
embeddings = retrieval_model(**batch)
document_embeddings.extend(list(torch.unbind(embeddings.to("cpu"))))
# Return summary, document embeddings, and images
return document_embeddings, images
These embeddings which are high-dimensional representations of the visual content of each page, are then moved to the CPU and unbound into a list.
The function ultimately returns a tuple containing a list of generated embeddings, and the list of images. This process facilitates the conversion of document pages into a form that can be efficiently searched and retrieved based on their content.
Indexing Process :
To index the documents we convert each page of the PDF into an image and then generate embeddings for these images using our pre-trained retrieval model.
import os
DATA_FOLDER = "data"
pdf_files = pdf_files = [os.path.join(DATA_FOLDER, file) for file in os.listdir(DATA_FOLDER) if file.lower().endswith('.pdf')]
document_embeddings, images = index(pdf_files)
Retrieve Top Document
retrieve_top_document function retrieves the most relevant pages from a set of indexed document pages based on a user's query , it begins by initializing an empty list for the query embeddings and creating a placeholder image to maintain input consistency , the query string is then processed using a processor, transforming it into a format suitable for the model ,this processed query is moved to the appropriate device for inference, where the retrieval model generates embeddings for the query.
def retrieve_top_document(query: str, document_embeddings: List[torch.Tensor], document_images: List[Image.Image]) -> Tuple[str, Image.Image]:
query_embeddings = []
# Create a placeholder image
placeholder_image = Image.new("RGB", (448, 448), (255, 255, 255))
with torch.no_grad():
# Process the query to obtain embeddings
query_batch = process_queries(processor, [query], placeholder_image)
query_batch = {key: value.to(device) for key, value in query_batch.items()}
query_embeddings_tensor = retrieval_model(**query_batch)
query_embeddings = list(torch.unbind(query_embeddings_tensor.to("cpu")))
# Evaluate the embeddings to find the most relevant document
evaluator = CustomEvaluator(is_multi_vector=True)
similarity_scores = evaluator.evaluate(query_embeddings, document_embeddings)
# Identify the index of the highest scoring document
best_index = int(similarity_scores.argmax(axis=1).item())
# Return the best matching document text and image
return document_images[best_index]
These embeddings are then converted to a list and stored , next the function uses a custom evaluator, evaluator to compare the query embeddings against the document embeddings (document_embeddings), the evaluator scores each document page based on its relevance to the query , in the end the page with the highest relevance score is identified and its corresponding image is returned.
This function efficiently finds and returns the most relevant document page (image) in response to a user's query by leveraging advanced embedding techniques and custom evaluation metrics.
Generate Answer Function
import google.generativeai as genai
generation_config = {
"temperature": 0.0,
"top_p": 0.95,
"top_k": 64,
"max_output_tokens": 10,
"response_mime_type": "text/plain",
}
genai.configure(api_key="xxxxxxxxxxxxxxxx")
model = genai.GenerativeModel(model_name="gemini-1.5-flash" , generation_config=generation_config)
def get_answer(prompt:str , image:Image):
response = model.generate_content([prompt, image])
return response.text
This get_answer function sets up a generative model using Google's Generative AI service to generate text responses from combined textual prompts and images, utilizing a specific configuration to control the output's randomness, diversity, and length.
Answer Query
The answer_query function is designed to answer a user's query by retrieving the most relevant document and generating a text response based on it.
def answer_query(query: str) -> Tuple[str, Image.Image]:
# Retrieve the most relevant document based on the query
best_image = retrieve_top_document(query=query,
document_embeddings=document_embeddings,
document_images=images)
# Generate an answer using the retrieved document
answer = get_answer(query, best_image)
return answer, best_image
answer_query function returns a tuple containing the generated answer and the image of the most relevant document , this function effectively combines document retrieval and generative response generation to handle user queries with visually rich documents.
You can test it by running the following code:
answer, best_image = answer_query(query = "Ask Any thing about your documents")
print(answer)
best_image
Create a Gradio Interface
This simple interface allows users to easily interact with our system , leveraging its capabilities to process queries and provide contextually relevant answers along with visual document references.
import gradio as gr
interface = gr.Interface(
fn=answer_query,
inputs=gr.Textbox(label="Ask me About your Documents:", placeholder="Enter your query here..."),
outputs=[
gr.Textbox(label="Response"),
gr.Image(type="pil", label="Image")
],
title="Colpali RAG",
description="ColPali: Visual Retriever based on PaliGemma-3B with ColBERT strategy",
theme="default",
)
interface.launch()
- User Interaction: users type their queries into the text box and submit them.
- Query Processing: the
answer_queryfunction is called with the user's query , it retrieves the most relevant document based on the query and generates a text response using the document. - Response Display: the generated text response and the image of the most relevant document are displayed in the respective output components.