Microsoft GraphRAG and Ollama: Code Your Way to Smarter Question Answering
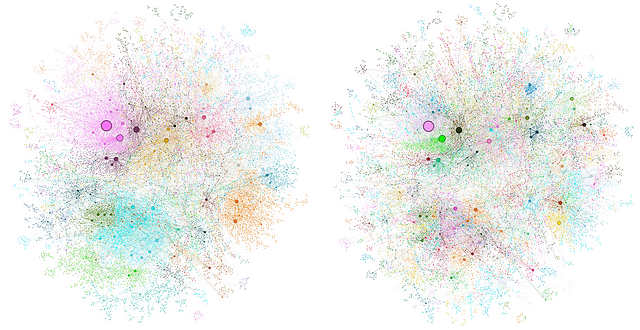
Traditional RAG methods, which primarily rely on semantic similarity search, often fall short when faced with complex questions that require connecting disparate pieces of information or understanding the broader context of a large dataset. Enter GraphRAG, a novel approach that leverages the power of knowledge graphs to overcome these limitations and enhance the capabilities of RAG systems.
Understanding the Problem with Baseline RAG
Baseline RAG systems, while useful for simple question answering, struggle when tasked with synthesizing information from various sources or understanding the overarching themes within a dataset. For example, if you ask a baseline RAG system "What are the main causes of climate change according to this research dataset?", it might struggle to provide a comprehensive answer because it lacks the ability to connect the different pieces of information related to climate change scattered throughout the dataset. This highlights the need for a more structured and intelligent approach to RAG.
A Knowledge Graph-Powered Solution
GraphRAG addresses this need by utilizing LLMs to extract a knowledge graph from the raw text data. This knowledge graph represents the information as a network of interconnected entities and relationships, providing a richer representation of the data compared to simple text snippets. This structured representation allows GraphRAG to excel at answering complex questions that require reasoning and connecting different pieces of information.
GraphRAG Architecture
GraphRAG's architecture consists of several key components. The GraphRAG Knowledge Model defines a standardized data model for representing entities like documents, TextUnits, entities, relationships, and community reports. DataShaper Workflows, built on the DataShaper library, enable declarative data processing, making the pipeline flexible and customizable. LLM-Based Workflow Steps integrate LLMs into the indexing process, using custom verbs to perform tasks like entity extraction and summarization.
Deep Dive into the GraphRAG Process
The GraphRAG process involves two main stages: indexing and querying.
Indexing:
During indexing, the input text is divided into manageable chunks called TextUnits. LLMs then extract entities, relationships, and claims from these TextUnits, forming the knowledge graph.
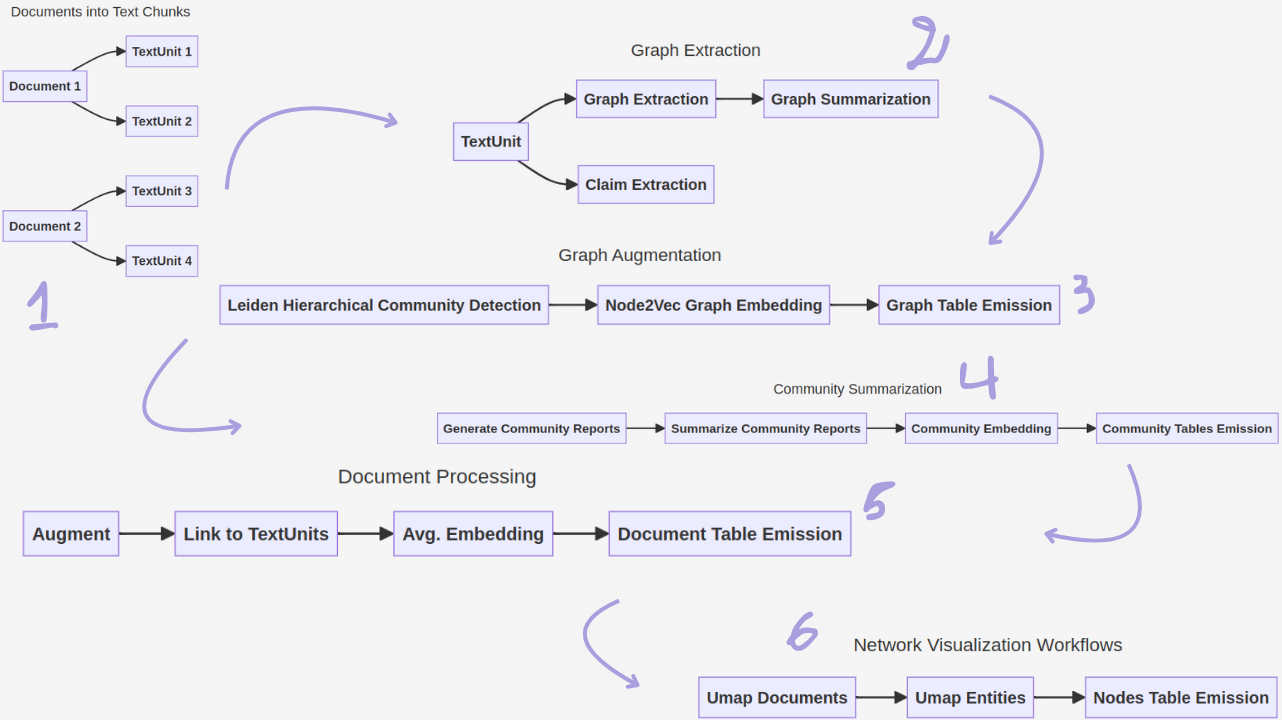
Furthermore, a process called community detection identifies clusters of related entities, and summaries are generated for each community, providing high-level overviews of different topics within the dataset.
Querying:
When a user submits a query, GraphRAG leverages the knowledge graph to retrieve relevant information. It offers two main search methods: Local Search and Global Search.
Local Search focuses on answering questions about specific entities, exploring their relationships, associated claims, and relevant text snippets.
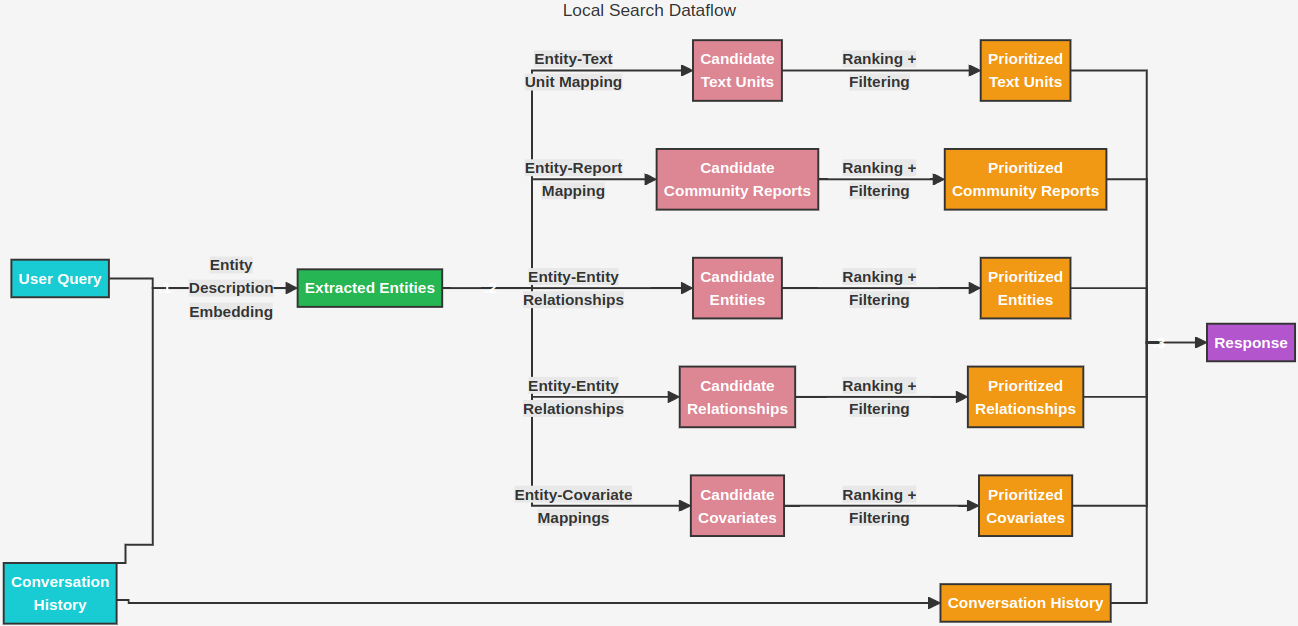
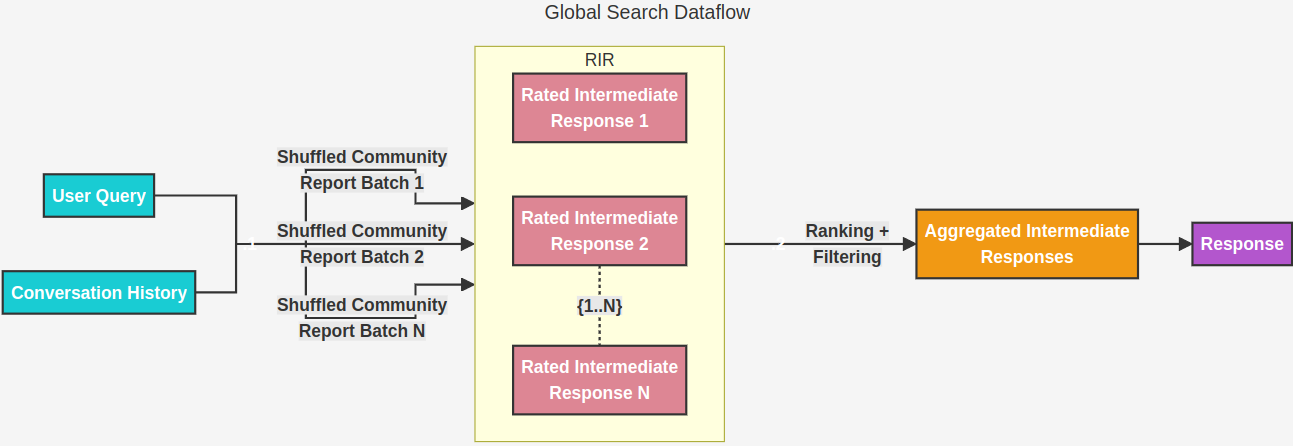
Global Search, on the other hand, tackles broader questions that require understanding the entire dataset. It analyzes the community summaries to identify overarching themes and synthesize information from across the dataset.
Benefits and Advantages of GraphRAG
By utilizing a knowledge graph, GraphRAG offers significant advantages over baseline RAG. It enhances reasoning capabilities by enabling the system to connect disparate pieces of information and synthesize new insights. It provides a holistic understanding of the dataset by organizing information into meaningful clusters and providing summaries for each cluster. Moreover, it improves overall RAG performance, particularly in complex question answering scenarios.
Applications and Use Cases
The applications of GraphRAG are vast and span various domains. In research, it can help answer complex questions by synthesizing information from large datasets of scientific papers. In enterprise settings, it can power conversational AI systems that can reason about specific domains, such as customer support or internal knowledge bases. Furthermore, GraphRAG can be used to create knowledge exploration tools that facilitate deeper understanding of large datasets, enabling users to interactively explore the relationships between different concepts and discover new insights.
Code Example
We begin by installing Ollama, a tool for running large language models locally, and starting its server.
curl -fsSL https://ollama.com/install.sh | sh
Start the server :
ollama serve
We then download the llama3.1 model for text generation and bge-large for embeddings.
ollama pull llama3.1
ollama pull bge-large
You can use ollama using Docker :
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
docker exec -it ollama ollama pull llama3.1
docker exec -it ollama ollama pull bge-large
Next, we install the GraphRAG library itself.
pip install graphrag
We create a directory for our project and a subdirectory for input data.
mkdir -p ./ragtest/input
A sample story is saved as a text file within the input folder.
text = """
In the city of Novus, a renowned architect named Alice Johnson was busy working on her latest project. Alice had been designing buildings for over 15 years and was well-known for her collaboration with her mentor, Robert Lee, who was also a famous architect. Robert had taught Alice everything she knew, and they remained close friends.
Alice was married to David Johnson, a software engineer who worked at TechCorp. David was passionate about his work and often collaborated with his colleague, Emily Smith, a data scientist at TechCorp. Emily was also Alice’s best friend from college, where they studied together. She frequently visited Alice and David’s home, and they often discussed their work over dinner.
Alice and David had a daughter, Sophie Johnson, who was 8 years old and loved spending time with her grandparents, John and Mary Johnson. John was David’s father, a retired professor, and Mary was a retired nurse. They lived in a neighboring town called Greenville and visited their family in Novus every weekend.
One day, Alice received an invitation from the Novus City Council to present her latest building design. She was excited to showcase her work and immediately contacted Robert Lee to review her plans. Robert was delighted to help, as he had always admired Alice’s talent. Meanwhile, David was busy at TechCorp, where he and Emily were working on a new AI project under the supervision of their manager, Michael Brown.
As the day of the presentation approached, Alice prepared her designs with Robert’s guidance. David and Sophie also attended the event to support Alice. The Novus City Council was impressed with her work and decided to approve the project, marking another success for Alice. After the event, the family celebrated with a dinner at their favorite restaurant, The Green Olive, where they were joined by Emily and Robert.
"""
with open("./ragtest/input/story.txt", "w") as f:
f.write(text)
GraphRAG is then initialized within the project directory, creating necessary configuration files.
python -m graphrag.index --init --root ./ragtest
The .env file is edited to include any required API keys.
GRAPHRAG_API_KEY=EMPTY
The settings.yaml file is modified to specify the models downloaded earlier (llama3.1 and bge-large), their local server endpoint, and other parameters like maximum tokens and concurrency. These settings configure GraphRAG to use Ollama for both text generation and embeddings.
LLMS:
- model : llama3.1
- max_tokens: 2000
- api_base: http://127.0.0.1:11434/v1 (ollama server endpoint)
- max_retries: 1
- concurrent_requests: 1
- comment this line
model_supports_json: true
Embeddings:
- model: bge-large:latest
- api_base: http://127.0.0.1:11434/v1
- max_retries: 1
- concurrent_requests: 1
- batch_size: 1
- batch_max_tokens: 8191
settings.yaml :
encoding_model: cl100k_base
skip_workflows: []
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_chat # or azure_openai_chat
model: llama3.1
# model_supports_json: true # recommended if this is available for your model.
max_tokens: 2000
# request_timeout: 180.0
api_base: http://127.0.0.1:11434/v1
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
max_retries: 1
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
concurrent_requests: 1 # the number of parallel inflight requests that may be made
parallelization:
stagger: 0.3
# num_threads: 50 # the number of threads to use for parallel processing
async_mode: threaded # or asyncio
embeddings:
## parallelization: override the global parallelization settings for embeddings
async_mode: threaded # or asyncio
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_embedding # or azure_openai_embedding
model: bge-large:latest
api_base: http://127.0.0.1:11434/v1
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
max_retries: 1
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
concurrent_requests: 1 # the number of parallel inflight requests that may be made
batch_size: 1 # the number of documents to send in a single request
batch_max_tokens: 8191 # the maximum number of tokens to send in a single request
# target: required # or optional
chunks:
size: 300
overlap: 100
group_by_columns: [id] # by default, we don't allow chunks to cross documents
input:
type: file # or blob
file_type: text # or csv
base_dir: "input"
file_encoding: utf-8
file_pattern: ".*\\.txt$"
cache:
type: file # or blob
base_dir: "cache"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
storage:
type: file # or blob
base_dir: "output/${timestamp}/artifacts"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
reporting:
type: file # or console, blob
base_dir: "output/${timestamp}/reports"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
entity_extraction:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/entity_extraction.txt"
entity_types: [organization,person,geo,event]
max_gleanings: 0
summarize_descriptions:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/summarize_descriptions.txt"
max_length: 500
claim_extraction:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
# enabled: true
prompt: "prompts/claim_extraction.txt"
description: "Any claims or facts that could be relevant to information discovery."
max_gleanings: 0
community_report:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/community_report.txt"
max_length: 2000
max_input_length: 7000
cluster_graph:
max_cluster_size: 10
embed_graph:
enabled: false # if true, will generate node2vec embeddings for nodes
# num_walks: 10
# walk_length: 40
# window_size: 2
# iterations: 3
# random_seed: 597832
umap:
enabled: false # if true, will generate UMAP embeddings for nodes
snapshots:
graphml: false
raw_entities: false
top_level_nodes: false
local_search:
# text_unit_prop: 0.5
# community_prop: 0.1
# conversation_history_max_turns: 5
# top_k_mapped_entities: 10
# top_k_relationships: 10
# max_tokens: 12000
global_search:
# max_tokens: 12000
# data_max_tokens: 12000
# map_max_tokens: 1000
# reduce_max_tokens: 2000
# concurrency: 32
Running the Indexing pipeline :
The GraphRAG indexing pipeline is executed, processing the story text. This involves creating TextUnits, extracting entities and relationships, building a community hierarchy, and generating summaries. The resulting knowledge graph and related data are stored in the specified output directory.
python -m graphrag.index --root ./ragtest
Finally, we can query the indexed data using either Global or Local Search. Global Search is used to ask questions about the overall story ("What are the top themes...?"), while Local Search is suitable for questions about specific entities ("Who is Scrooge...?"). The chosen search method retrieves relevant information from the knowledge graph and generates a response based on the query.
Global search using CLI :
python -m graphrag.query --root ./ragtest --method global "What are the top themes in this story?"
Local search using CLI:
python -m graphrag.query --root ./ragtest --method local "Who is Scrooge, and what are his main relationships?"
Global Search example
Global search method generates answers by searching over all AI-generated community reports in a map-reduce fashion. This is a resource-intensive method, but often gives good responses for questions that require an understanding of the dataset as a whole (e.g. What are the most significant values of the herbs mentioned in this notebook?).
1. Importing Dependencies and Setting up the LLM:
We begin by importing necessary libraries, including pandas for data manipulation, tiktoken for tokenization, and components from the graphrag library for query execution.
import os
import pandas as pd
import tiktoken
from graphrag.query.indexer_adapters import read_indexer_entities, read_indexer_reports
from graphrag.query.llm.oai.chat_openai import ChatOpenAI
from graphrag.query.llm.oai.typing import OpenaiApiType
from graphrag.query.structured_search.global_search.community_context import (
GlobalCommunityContext,
)
from graphrag.query.structured_search.global_search.search import GlobalSearch
We then initialize an instance of ChatOpenAI, configuring it to use the llama2.1 model hosted locally via Ollama.
api_key = "EMPTY"
llm_model = "llama3.1"
llm = ChatOpenAI(
api_base="http://127.0.0.1:11434/v1",
api_key=api_key,
model=llm_model,
api_type=OpenaiApiType.OpenAI,
max_retries=20,
)
token_encoder = tiktoken.get_encoding("cl100k_base")
A basic test ensures the LLM endpoint is functioning correctly.
messages = [
{
"role": "user",
"content": "Hi"
}
]
response = llm.generate(messages=messages)
print(response)
2. Loading Data and Building the Context:
Next, we load the community reports and entity data generated during the indexing phase. These reports, organized hierarchically, represent different aspects of the dataset. We specify COMMUNITY_LEVEL to determine the granularity of the reports used.
# parquet files generated from indexing pipeline
INPUT_DIR = "./output/run-id" # replace the run-id with the created one
COMMUNITY_REPORT_TABLE = "artifacts/create_final_community_reports"
ENTITY_TABLE = "artifacts/create_final_nodes"
ENTITY_EMBEDDING_TABLE = "artifacts/create_final_entities"
# community level in the Leiden community hierarchy from which we will load the community reports
# higher value means we use reports from more fine-grained communities (at the cost of higher computation cost)
COMMUNITY_LEVEL = 2
entity_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_TABLE}.parquet")
report_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_REPORT_TABLE}.parquet")
entity_embedding_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_EMBEDDING_TABLE}.parquet")
reports = read_indexer_reports(report_df, entity_df, COMMUNITY_LEVEL)
entities = read_indexer_entities(entity_df, entity_embedding_df, COMMUNITY_LEVEL)
# Build global context based on community reports
context_builder = GlobalCommunityContext(
community_reports=reports,
entities=entities, # default to None if you don't want to use community weights for ranking
token_encoder=token_encoder,
)
The GlobalCommunityContext is then initialized, responsible for selecting and formatting relevant community reports as context for the LLM.
3. Configuring Global Search:
We define parameters for the context builder, map stage, and reduce stage of Global Search. These parameters control aspects like context size, shuffling of reports, inclusion of community rankings and weights, and LLM parameters for each stage.
context_builder_params = {
"use_community_summary": False, # False means using full community reports. True means using community short summaries.
"shuffle_data": True,
"include_community_rank": True,
"min_community_rank": 0,
"community_rank_name": "rank",
"include_community_weight": True,
"community_weight_name": "occurrence weight",
"normalize_community_weight": True,
"max_tokens": 1000, # change this based on the token limit you have on your model (if you are using a model with 8k limit, a good setting could be 5000)
"context_name": "Reports",
}
map_llm_params = {
"max_tokens": 1000,
"temperature": 0.0,
"response_format": {"type": "json_object"},
}
reduce_llm_params = {
"max_tokens": 2000, # change this based on the token limit you have on your model (if you are using a model with 8k limit, a good setting could be 1000-1500)
"temperature": 0.0,
}
search_engine = GlobalSearch(
llm=llm,
context_builder=context_builder,
token_encoder=token_encoder,
max_data_tokens=1000, # change this based on the token limit you have on your model (if you are using a model with 8k limit, a good setting could be 5000)
map_llm_params=map_llm_params,
reduce_llm_params=reduce_llm_params,
allow_general_knowledge=False, # set this to True will add instruction to encourage the LLM to incorporate general knowledge in the response, which may increase hallucinations, but could be useful in some use cases.
json_mode=True, # set this to False if your LLM model does not support JSON mode.
context_builder_params=context_builder_params,
concurrent_coroutines=32,
response_type="multiple paragraphs", # free form text describing the response type and format, can be anything, e.g. prioritized list, single paragraph, multiple paragraphs, multiple-page report
)
We then create the GlobalSearch engine, passing in the LLM instance, context builder, tokenizer, and other configuration parameters.
4. Performing Global Search:
We execute the Global Search using the asearch method, providing the query "Who has collaborated with Alice Johnson on any project?".
result = await search_engine.asearch(
"Who has collaborated with Alice Johnson on any project?"
)
print(result.response)
The search engine retrieves relevant community reports, extracts key points, aggregates them, and generates a final response based on the aggregated information.
print the number of llms call and tokens :
print(f"LLM calls: {result.llm_calls}. LLM tokens: {result.prompt_tokens}")
Local Search Example
1. Importing Dependencies and Setting up the Environment:
We begin by importing necessary libraries, including components from the graphrag library for handling various aspects of the query process. We set the stage for Local Search, which is ideal for questions requiring detailed information about particular entities.
import os
import pandas as pd
import tiktoken
from graphrag.query.context_builder.entity_extraction import EntityVectorStoreKey
from graphrag.query.indexer_adapters import (
read_indexer_covariates,
read_indexer_entities,
read_indexer_relationships,
read_indexer_reports,
read_indexer_text_units,
)
from graphrag.query.input.loaders.dfs import (
store_entity_semantic_embeddings,
)
from graphrag.query.llm.oai.chat_openai import ChatOpenAI
from graphrag.query.llm.oai.embedding import OpenAIEmbedding
from graphrag.query.llm.oai.typing import OpenaiApiType
from graphrag.query.question_gen.local_gen import LocalQuestionGen
from graphrag.query.structured_search.local_search.mixed_context import (
LocalSearchMixedContext,
)
from graphrag.query.structured_search.local_search.search import LocalSearch
from graphrag.vector_stores.lancedb import LanceDBVectorStore
2. Loading Data and Building the Context:
We load data from the indexing pipeline's output, including entities, relationships, community reports, and text units. These data sources provide a comprehensive view of the indexed information.
# Load tables to dataframes
INPUT_DIR = "./output/run-id" # replace the run id with the created one
LANCEDB_URI = f"{INPUT_DIR}/lancedb"
COMMUNITY_REPORT_TABLE = "artifacts/create_final_community_reports"
ENTITY_TABLE = "artifacts/create_final_nodes"
ENTITY_EMBEDDING_TABLE = "artifacts/create_final_entities"
RELATIONSHIP_TABLE = "artifacts/create_final_relationships"
COVARIATE_TABLE = "artifacts/create_final_covariates"
TEXT_UNIT_TABLE = "artifacts/create_final_text_units"
COMMUNITY_LEVEL = 2
# Read entities
# read nodes table to get community and degree data
entity_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_TABLE}.parquet")
entity_embedding_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_EMBEDDING_TABLE}.parquet")
entities = read_indexer_entities(entity_df, entity_embedding_df, COMMUNITY_LEVEL)
# load description embeddings to an in-memory lancedb vectorstore
# to connect to a remote db, specify url and port values.
description_embedding_store = LanceDBVectorStore(
collection_name="entity_description_embeddings",
)
description_embedding_store.connect(db_uri=LANCEDB_URI)
entity_description_embeddings = store_entity_semantic_embeddings(
entities=entities, vectorstore=description_embedding_store
)
# Read relationships
relationship_df = pd.read_parquet(f"{INPUT_DIR}/{RELATIONSHIP_TABLE}.parquet")
relationships = read_indexer_relationships(relationship_df)
# NOTE: covariates are turned off by default, because they generally need prompt tuning to be valuable
# Please see the GRAPHRAG_CLAIM_* settings
# covariate_df = pd.read_parquet(f"{INPUT_DIR}/{COVARIATE_TABLE}.parquet")
#claims = read_indexer_covariates(covariate_df)
report_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_REPORT_TABLE}.parquet")
reports = read_indexer_reports(report_df, entity_df, COMMUNITY_LEVEL)
# Read text units
text_unit_df = pd.read_parquet(f"{INPUT_DIR}/{TEXT_UNIT_TABLE}.parquet")
text_units = read_indexer_text_units(text_unit_df)
We leverage LanceDB, a vector database, to store and efficiently retrieve entity embeddings, which are crucial for identifying entities related to the user's query.
3. Configuring the Embedding Model:
We initialize an OpenAIEmbedding instance, configuring it to use the bge-large model hosted locally via Ollama. This model will be used to generate embeddings for text, allowing us to find semantically similar entities and text units during the search process.
embedding_model = "bge-large:latest"
text_embedder = OpenAIEmbedding(
api_key=api_key,
api_base="http://127.0.0.1:11434/v1",
api_type=OpenaiApiType.OpenAI,
model=embedding_model,
deployment_name=embedding_model,
max_retries=20,
)
4. Creating the Local Search Context Builder:
We create a LocalSearchMixedContext instance, providing it with access to the loaded data (entities, relationships, reports, text units) and the embedding model. This context builder is responsible for selecting and formatting relevant information from these sources based on the user's query.
context_builder = LocalSearchMixedContext(
community_reports=reports,
text_units=text_units,
entities=entities,
relationships=relationships,
# if you did not run covariates during indexing, set this to None
covariates=None,
entity_text_embeddings=description_embedding_store,
embedding_vectorstore_key=EntityVectorStoreKey.ID, # if the vectorstore uses entity title as ids, set this to EntityVectorStoreKey.TITLE
text_embedder=text_embedder,
token_encoder=token_encoder,
)
5. Creating the Local Search Engine:
We initialize the LocalSearch engine, providing the LLM, context builder, tokenizer, and specific parameters that control how the search is performed. These parameters determine factors like the proportion of the context window dedicated to different data types (e.g., text units vs. community reports), the number of related entities to retrieve, and the maximum context window size.
text_unit_prop: proportion of context window dedicated to related text unitscommunity_prop: proportion of context window dedicated to community reports. The remaining proportion is dedicated to entities and relationships. Sum of text_unit_prop and community_prop should be <= 1conversation_history_max_turns: maximum number of turns to include in the conversation history.conversation_history_user_turns_only: if True, only include user queries in the conversation history.top_k_mapped_entities: number of related entities to retrieve from the entity description embedding store.top_k_relationships: control the number of out-of-network relationships to pull into the context window.include_entity_rank: if True, include the entity rank in the entity table in the context window. Default entity rank = node degree.include_relationship_weight: if True, include the relationship weight in the context window.include_community_rank: if True, include the community rank in the context window.return_candidate_context: if True, return a set of dataframes containing all candidate entity/relationship/covariate records that could be relevant. Note that not all of these records will be included in the context window. The "in_context" column in these dataframes indicates whether the record is included in the context window.max_tokens: maximum number of tokens to use for the context window.
local_context_params = {
"text_unit_prop": 0.5,
"community_prop": 0.1,
"conversation_history_max_turns": 5,
"conversation_history_user_turns_only": True,
"top_k_mapped_entities": 10,
"top_k_relationships": 10,
"include_entity_rank": True,
"include_relationship_weight": True,
"include_community_rank": False,
"return_candidate_context": False,
"embedding_vectorstore_key": EntityVectorStoreKey.ID, # set this to EntityVectorStoreKey.TITLE if the vectorstore uses entity title as ids
"max_tokens": 12_000, # change this based on the token limit you have on your model (if you are using a model with 8k limit, a good setting could be 5000)
}
llm_params = {
"max_tokens": 2_000, # change this based on the token limit you have on your model (if you are using a model with 8k limit, a good setting could be 1000=1500)
"temperature": 0.0,
}
search_engine = LocalSearch(
llm=llm,
context_builder=context_builder,
token_encoder=token_encoder,
llm_params=llm_params,
context_builder_params=local_context_params,
response_type="multiple paragraphs", # free form text describing the response type and format, can be anything, e.g. prioritized list, single paragraph, multiple paragraphs, multiple-page report
)
6. Running Local Search:
Finally, we execute the Local Search using the asearch method, providing the query "Tell me about Alice Johnson". The search engine identifies relevant entities (Alice Johnson in this case), retrieves related information from the various data sources, and generates a comprehensive response based on the combined context.
question = "Tell me about Alice Johnson"
result = await search_engine.asearch(question)
print(result.response)
GraphRAG represents a significant advancement in the field of Retrieval Augmented Generation. By leveraging knowledge graphs, it overcomes the limitations of traditional RAG methods and empowers LLMs to reason more effectively, understand complex datasets holistically, and provide more accurate and insightful answers to a wide range of questions. As research and development in this area continue, we can expect GraphRAG to play an increasingly important role in shaping the future of AI-powered knowledge retrieval and exploration.