Accelerating PyTorch Inference with Speed and Simplicity
In the fast-paced world of deep learning, squeezing every ounce of performance from your models is crucial. Torch-TensorRT empowers you to do just that, delivering significant inference speedups for your PyTorch models on NVIDIA GPUs. With its ease of use and powerful optimization capabilities, Torch-TensorRT bridges the gap between PyTorch's flexibility and TensorRT's raw performance.
What is Torch-TensorRT?
Torch-TensorRT is a powerful inference compiler that seamlessly integrates with PyTorch, allowing you to leverage the high-performance optimizations of NVIDIA's TensorRT deep learning inference platform. By converting compatible portions of your PyTorch model into optimized TensorRT engines, Torch-TensorRT unlocks significant performance gains without sacrificing the flexibility and ease of use of the PyTorch ecosystem.
How Torch-TensorRT Works: A Three-Phase Optimization Process
Torch-TensorRT's magic lies in its intelligent three-phase optimization process:
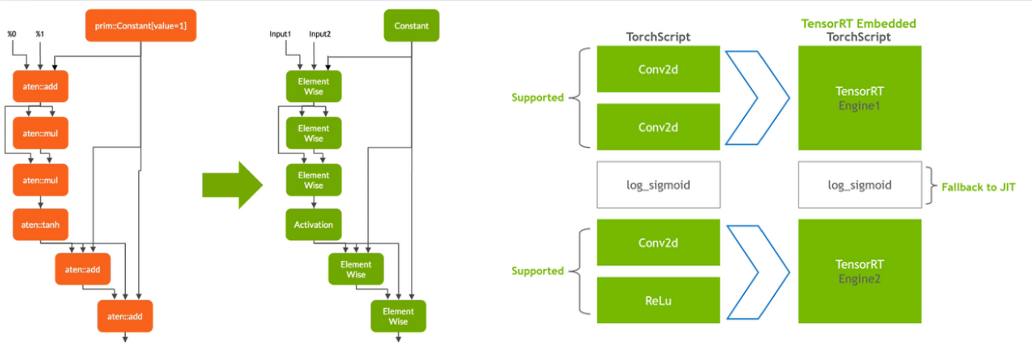
Lowering: The TorchScript module representing your PyTorch model is simplified, optimizing common operations for efficient mapping to TensorRT. This process maintains the functionality of your model while preparing it for conversion.

Conversion: Torch-TensorRT identifies compatible subgraphs within your model and translates them into highly optimized TensorRT engines. Static values are converted to constants, tensor computations are mapped to efficient TensorRT layers, and the remaining parts of the model remain in TorchScript, creating a hybrid execution graph.
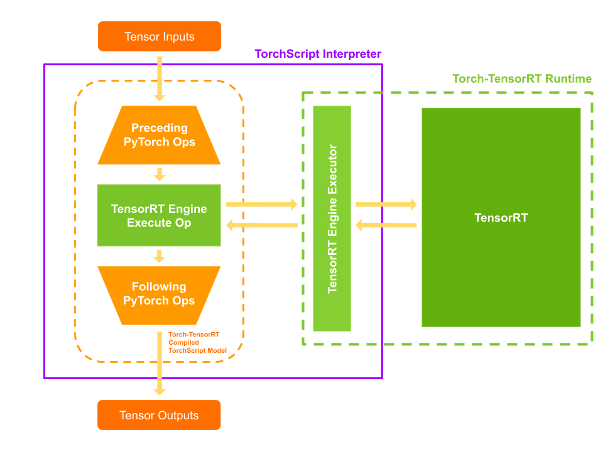
Execution: When you run your compiled model, the TorchScript interpreter seamlessly interacts with the embedded TensorRT engines. Data flows through the optimized TensorRT portions for maximum performance, while the remaining PyTorch code executes natively, ensuring complete functionality.
Key Features: Power and Flexibility at Your Fingertips
Torch-TensorRT offers a range of powerful features to enhance your inference workflow:
-
INT8 Support: Leverage lower precision inference with INT8 quantization, reducing memory footprint and accelerating computations without significant accuracy loss. Choose between post-training quantization (PTQ) and quantization-aware training (QAT) for optimal results.
-
Sparsity: Harness the power of NVIDIA Ampere architecture GPUs with support for sparsity in convolutional and fully connected layers, maximizing throughput and efficiency.
-
FX and TorchScript Frontends: Choose the frontend that best suits your needs. The FX frontend provides a Python-based workflow for easy customization and extensibility, while the TorchScript frontend offers benefits like Pythonless execution and a single portable artifact.
Code Examples
Installing Necessary Packages:
Here we install the required packages for using Torch-TensorRT. This includes both the torch-tensorrt package itself, which provides the integration between PyTorch and TensorRT, and the tensorrt package, which contains the NVIDIA TensorRT libraries and runtime.
python -m pip install torch-tensorrt tensorrt
Importing Necessary Libraries:
After that, we import the necessary libraries. torch and torch.nn are the fundamental PyTorch libraries for deep learning.
import torch
import torch.nn as nn
import torch_tensorrt
import time
torch_tensorrt is the library that enables the integration with TensorRT.
Finally, time is used for measuring inference times.
Hugging Face models example 🤗
Loading a Hugging Face BERT Model:
Here we use the Hugging Face transformers library to easily load a pre-trained BERT model (bert-base-uncased). We set the model to evaluation mode using .eval() and move it to the GPU using .to("cuda").
from transformers import BertModel
# Load and prepare the model
model = BertModel.from_pretrained("bert-base-uncased").eval().to("cuda")
Now we define sample inputs for the BERT model. input_ids represents the tokenized input sequence, and attention_mask indicates which tokens should be attended to. Both tensors are created on the GPU using .cuda().
# Define sample inputs for the model (using FP32)
input_ids = torch.randint(0, 1000, (8, 32), dtype=torch.long).cuda() # (batch_size, sequence_length)
attention_mask = torch.ones((8, 32), dtype=torch.long).cuda() # (batch_size, sequence_length)
Measuring Baseline Inference Time:
We measure the baseline inference time of the original PyTorch model. The time.time() function is used to record the start and end times, and the difference gives us the inference time.
# Measure inference time for the normal model
start_time = time.time()
normal_output = model(input_ids, attention_mask=attention_mask)
normal_time = (time.time() - start_time)
print(f"Normal model inference time: {normal_time:.6f} seconds")
The output :
Normal model inference time: 0.043182 seconds
Compiling the Model with Torch-TensorRT:
Here we utilize the torch_tensorrt.compile() function to compile the PyTorch model using the Torch-TensorRT backend. We specify various options, including the desired precision (torch.float for FP32), debug settings, block size, workspace size, and support for dynamic shapes.
# Compile the model using torch_tensorrt.compile with Torch-TensorRT as backend
backend_kwargs = {
"enabled_precisions": {torch.float}, # Use float32 precision
"debug": False, # Enable debug logs
"min_block_size": 2, # Adjust block size
"workspace_size": 20 << 30, # 20 GB workspace
}
optimized_model = torch_tensorrt.compile(
model,
inputs=[input_ids, attention_mask],
backend="torch_tensorrt",
options=backend_kwargs,
dynamic=True, # Set to True if you want dynamic shapes support
)
Measuring Optimized Inference Time:
Finally, we measure the inference time of the optimized model using the same inputs as before.
# Measure inference time for the normal model
start_time = time.time()
normal_output = optimized_model(input_ids, attention_mask=attention_mask)
normal_time = (time.time() - start_time)
print(f"Optimized model inference time: {optimized_time:.6f} seconds")
The output :
Optimized model inference time: 0.002214 seconds
This allows us to compare the performance improvement achieved by Torch-TensorRT.
Custum Model Example
Defining a Custom Transformer Model:
Here we define a custom transformer model, SimpleTransformer, utilizing PyTorch's nn.Module. This model includes an embedding layer, a standard transformer encoder, and a final linear layer for output.
# Define the SimpleTransformer class
class SimpleTransformer(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads, num_layers, output_dim):
super(SimpleTransformer, self).__init__()
self.embedding = nn.Embedding(input_dim, embed_dim)
self.transformer = nn.Transformer(embed_dim, num_heads, num_layers)
self.fc = nn.Linear(embed_dim, output_dim)
def forward(self, src, tgt):
src_emb = self.embedding(src)
tgt_emb = self.embedding(tgt)
transformer_out = self.transformer(src_emb, tgt_emb)
output = self.fc(transformer_out[-1]) # Get output from the last token
return output
# Model parameters
input_dim = 100
embed_dim = 512
num_heads = 8
num_layers = 6
output_dim = 10
# Initialize the model and move to GPU
model = SimpleTransformer(input_dim, embed_dim, num_heads, num_layers, output_dim).eval().cuda()
After defining the model's architecture and parameters, we instantiate it and move it to the GPU for accelerated computation.
Creating Sample Input Data:
We then create sample input tensors, src and tgt, representing the source and target sequences for the transformer. These tensors are initialized with random integers and moved to the GPU.
# Define sample inputs for the model (using FP32)
src = torch.randint(0, input_dim, (10, 32), dtype=torch.long).cuda() # (sequence_length, batch_size)
tgt = torch.randint(0, input_dim, (20, 32), dtype=torch.long).cuda() # (sequence_length, batch_size)
Initial Model Run (Warm-up):
# The first run
normal_output = model(src, tgt)
This initial run serves as a warm-up for the model, allowing for any necessary initialization or optimizations to occur before measuring performance.
Measuring Baseline Inference Time:
Now we measure the baseline inference time of the custom PyTorch model. The with torch.no_grad() context disables gradient calculations, as we are only interested in inference performance.
# Measure inference time for the normal model
start_time = time.time()
with torch.no_grad():
normal_output = model(src, tgt)
normal_time = time.time() - start_time
print(f"Normal model inference time: {normal_time:.6f} seconds")
The output :
Normal model inference time: 0.017368 seconds
Compiling the Model with Torch-TensorRT:
Here, we use torch_tensorrt.compile() to optimize the model with the Torch-TensorRT backend, enabling FP16 precision and setting various configuration parameters.
# Compile the model using torch.compile with Torch-TensorRT as backend
backend_kwargs = {
"enabled_precisions": {torch.float16}, # Use float32 precision
"debug": False, # Enable debug logs
"min_block_size": 2, # Adjust block size
"workspace_size": 20 << 30, # 20 GB workspace
}
optimized_model = torch_tensorrt.compile(
model,
inputs= [src, tgt], # Pass inputs to define the model's input signature
backend="torch_tensorrt",
options=backend_kwargs,
dynamic=True, # Set to True if you want dynamic shapes support
)
# The first run
optimized_output = optimized_model(src, tgt)
An initial run with the optimized model is performed for warm-up purposes.
Measuring Optimized Inference Time:
We then measure the inference time of the optimized model, allowing us to compare it with the baseline performance and quantify the speedup achieved.
# Measure inference time for the optimized model
start_time = time.time()
with torch.no_grad():
optimized_output = optimized_model(src, tgt)
optimized_time = time.time() - start_time
print(f"Optimized model inference time: {optimized_time:.6f} seconds")
The output :
Optimized model inference time: 0.001882 seconds
Saving and Loading the Optimized Model (ExportedProgram and TorchScript):
ExportedProgram :
torch_tensorrt.save(optimized_model, "optimized_model.ep", inputs=[src, tgt])
# Later, you can load it and run inference
loaded_model = torch.export.load("optimized_model.ep").module()
Torchscript :
torch_tensorrt.save(optimized_model, "optimized_model.ts", output_format="torchscript",inputs=[src, tgt])
# Later, you can load it and run inference
loaded_model = torch.jit.load("optimized_model.ts").cuda()
These code snippets demonstrate how to save the optimized model in either the ExportedProgram (.ep) or TorchScript (.ts) format, and then load them back for later use.
# file_path can be trt.ep or trt.ts file obtained via saving the model (refer to the above section)
loaded_model = torch_tensorrt.load("optimized_model.ts")
# or :
loaded_model = torch_tensorrt.load("optimized_model.ep")
Performance Analysis
Performance Analysis on a Free Colab Tesla T4 GPU
BertModel: The original BertModel achieved an inference time of 0.043182 seconds. After optimization with Torch-TensorRT, the inference time was drastically reduced to 0.002214 seconds, representing a speedup of approximately 19.5x.
SimpleTransformer: The custom SimpleTransformer model initially had an inference time of 0.017368 seconds. After optimization, this was reduced to 0.001882 seconds, resulting in a speedup of approximately 9.2x.
These results clearly demonstrate the significant performance gains that can be achieved by utilizing Torch-TensorRT to optimize PyTorch models for inference on NVIDIA GPUs.
Why with torch.no_grad(): is Used
In the SimpleTransformer example, we used the with torch.no_grad(): context during inference time measurement. This is because, during inference, we are not interested in calculating gradients for backpropagation. Disabling gradient calculations reduces computational overhead and memory usage, leading to more accurate and efficient inference time measurements.
Essentially, with torch.no_grad(): tells PyTorch that we are in inference mode and that it doesn't need to track gradients for any operations within that context.
By incorporating Torch-TensorRT into your PyTorch workflows, you can unlock significant performance improvements for your deep learning models, especially when deploying them on NVIDIA GPUs. The ease of use and substantial speedups make it a valuable tool for any deep learning practitioner seeking to optimize inference performance.